
Resumen
En este artículo exploraremos la evolución de las arquitecturas de almacenamiento de datos, desde los almacenes de datos relacionales tradicionales (RDW) hasta las soluciones más modernas como los data lakes y el concepto emergente de data lakehouse. También discutiremos las fábricas de datos y el data mesh, y cómo estas arquitecturas abordan los desafíos de la gestión de datos en la actualidad.
1. Introducción
Según un estudio de Boston Consulting Group sobre nuevas arquitecturas para el manejo de datos realizado en 2023, el volumen de datos generados se duplicó aproximadamente entre 2018 y 2021, alcanzando alrededor de 84 ZB, una tasa de crecimiento que se espera continúe. Las empresas son conscientes de que pueden ahorrar millones de dólares y aumentar sus ingresos recopilando estos datos y utilizándolos para analizar el pasado y el presente, además de hacer predicciones sobre el futuro. Sin embargo, para lograrlo, necesitan una forma de almacenar todos esos datos.
El objetivo es proporcionar la información correcta a las personas adecuadas, en el momento adecuado y en el formato adecuado. Para lograr esto, es imprescindible contar con una arquitectura de datos que permita la ingestión, almacenamiento, transformación y modelado de los datos (procesamiento de big data), de manera que se puedan utilizar de forma precisa y sencilla. Se necesita una arquitectura que permita a cualquier usuario final, incluso aquellos con muy poco conocimiento técnico, analizar los datos y generar informes y paneles, en lugar de depender de personal de TI con conocimientos técnicos profundos para hacerlo.
1.1. Los datos son el nuevo petróleo
Los datos son como una materia prima que necesita ser extraída, refinada y procesada para ser útil. En el caso de los datos, esto implica recopilarlos, almacenarlos y analizarlos para obtener conocimientos que puedan impulsar decisiones empresariales.
Su valor es inmenso. Las empresas que recopilan y analizan grandes volúmenes de datos pueden utilizarlos para mejorar sus productos y servicios, tomar mejores decisiones comerciales y obtener una ventaja competitiva.
Además, los datos pueden emplearse de muchas maneras. Por ejemplo, si se utilizan para entrenar algoritmos de aprendizaje automático, esos algoritmos pueden automatizar tareas, identificar patrones y hacer predicciones.
Se trata de un recurso poderoso con un efecto transformador en la sociedad. Así como el uso generalizado del petróleo impulsó el crecimiento de las industrias y permitió el desarrollo de nuevas tecnologías, los datos han dado lugar a avances en campos como la inteligencia artificial, el aprendizaje automático y la analítica predictiva.
Debido a todos estos factores, los datos también pueden ser una fuente de poder e influencia.
Por ejemplo, con big data se pueden generar informes y paneles que indiquen dónde están bajando las ventas, y tomar medidas “después del hecho” para mejorar esas ventas. También es posible usar el aprendizaje automático para predecir dónde disminuirán las ventas en el futuro y tomar medidas proactivas para evitar esa caída. A esto se le llama inteligencia empresarial (Business Intelligence, BI): el proceso de recopilar, analizar y utilizar datos para ayudar a las empresas a tomar decisiones más informadas.
1.2. Madurez de los datos
En los útimos años se escucha bastante el término "transformación digital" en la industria de TI. Hace referencia a cómo las empresas integran tecnologías en todas sus áreas para generar un cambio fundamental en la forma en que extraen valor de los datos, operan y entregan valor a sus clientes. Esta transformación digital puede dividirse en cuatro etapas, conocidas como las fases de madurez de los datos empresariales:
|
Note
|
La madurez de los datos es un concepto que se refiere a la calidad y la utilidad de los datos. Los datos maduros son datos que se han limpiado, organizado y estructurado de manera que sean fáciles de usar y analizar. Los datos inmaduros, por otro lado, son datos que no se han limpiado ni organizado, lo que dificulta su uso y análisis. |
-
Etapa 1: Reactiva. En esta primera etapa, una empresa tiene datos dispersos por todas partes, generalmente en múltiples hojas de cálculo de Excel y/o bases de datos de escritorio en varios sistemas de archivos, que son compartidos por correo electrónico. Los arquitectos de datos llaman a esta situación un spreadmart (abreviatura de data mart de hojas de cálculo): una colección de datos informal y descentralizada que suele encontrarse en organizaciones que usan hojas de cálculo para almacenar, gestionar y analizar datos. Los spreadmarts suelen ser creados y mantenidos de manera independiente por individuos o equipos, sin conexión con el sistema centralizado de gestión de datos o el almacén de datos oficial de la organización. Este enfoque genera problemas de inconsistencia en los datos, falta de gobernanza, escalabilidad limitada e ineficiencia (debido a la duplicación de esfuerzos).
-
Etapa 2: Informativa. Las empresas alcanzan la segunda etapa de madurez cuando comienzan a centralizar sus datos, lo que facilita el análisis y la generación de informes. Las etapas 1 y 2 se centran en los informes históricos, es decir, en identificar tendencias y patrones del pasado, por lo que a menudo se las conoce como mirar por “el espejo retrovisor”. En estas etapas, las empresas reaccionan ante eventos ya ocurridos. En la etapa 2, las soluciones para recopilar datos no suelen ser muy escalables. Por lo general, el tamaño y los tipos de datos que pueden manejar son limitados, y la frecuencia de ingestión de datos es baja (por ejemplo, una vez por la noche). La mayoría de las empresas están en esta fase, especialmente si su infraestructura sigue estando en sus instalaciones (on-premise).
-
Etapa 3: Predictiva. En la tercera etapa, las empresas ya han migrado a la nube y han construido un sistema capaz de manejar mayores cantidades de datos, diferentes tipos de datos y que puede ingerirlos con mayor frecuencia (cada hora o en tiempo real mediante streaming). Además, han mejorado la toma de decisiones al incorporar aprendizaje automático (analítica avanzada), lo que les permite tomar decisiones en tiempo real. Por ejemplo, mientras un usuario está en una tienda de libros en línea, el sistema podría recomendar libros adicionales en la página de pago basándose en sus compras previas.
-
Etapa 4: Transformativa. Finalmente, en la cuarta etapa, la empresa ha desarrollado una solución que puede manejar cualquier tipo de datos, independientemente de su tamaño, velocidad o formato. Incorporar nuevos datos es un proceso ágil, ya que la arquitectura está preparada para gestionarlos, y la infraestructura tiene la capacidad necesaria para soportarlos. Esta solución permite a los usuarios finales no técnicos crear fácilmente informes y paneles con las herramientas que prefieran.
2. Arquitecturas de datos
Al construir una solución de datos, es fundamental contar con un plan bien diseñado, y es aquí donde entran en juego las arquitecturas de datos. Las arquitecturas de datos son un conjunto de reglas, políticas, estándares y prácticas que definen cómo se capturan, almacenan, gestionan y utilizan los datos en una organización. Estas arquitecturas son esenciales para garantizar que los datos sean precisos, consistentes, seguros y accesibles. Además, permiten a las organizaciones aprovechar al máximo sus datos y utilizarlos para tomar decisiones informadas. Las arquitecturas de datos definen un enfoque arquitectónico de alto nivel y un conjunto de tecnologías a utilizar, además de especificar el flujo de datos que se empleará para construir la solución y capturar grandes volúmenes de información (big data).
Las arquitecturas de datos se refieren al diseño general y la organización de los datos dentro de un sistema de información. Aunque las plantillas predefinidas de arquitecturas de datos pueden parecer una forma rápida de configurar un nuevo sistema, a menudo no logran contemplar los requisitos y restricciones específicos del sistema en el que se aplican. Esto puede ocasionar problemas en la calidad de los datos, el rendimiento del sistema y su mantenimiento.
Además, las necesidades de la organización y los sistemas de datos tienden a cambiar con el tiempo, lo que exige actualizaciones y ajustes en la arquitectura de datos. Una plantilla estandarizada podría no ser lo suficientemente flexible para adaptarse a estos cambios, lo que puede generar ineficiencias y limitaciones en el sistema.
2.1. Bases de datos relacionales
Una base de datos relacional almacena datos de manera estructurada, con relaciones entre los elementos de datos definidas mediante claves. Los datos suelen organizarse en tablas, donde cada tabla se compone de filas y columnas. Cada fila representa una instancia específica de los datos, mientras que cada columna representa un atributo particular de esos datos.
Las bases de datos relacionales están diseñadas para manejar datos estructurados y proporcionan un marco para crear, modificar y consultar los datos utilizando un lenguaje estandarizado conocido como SQL (Structured Query Language). El modelo relacional fue propuesto por primera vez por Edgar F. Codd en 1970, y desde mediados de los años 70 se ha convertido en el modelo dominante para los sistemas de gestión de bases de datos. La mayoría de las aplicaciones operacionales necesitan almacenar datos de manera permanente, y una base de datos relacional es la herramienta preferida por una gran mayoría para esta tarea.
|
Note
|
No obstante, las bases de datos relacionales tienen limitaciones en cuanto a la escalabilidad y el manejo de grandes volúmenes de datos no estructurados. Además, la estructura rígida de las bases de datos relacionales puede dificultar la adaptación a cambios en los requisitos de los datos. Es por ello que han surgido nuevos tipos de bases de datos, como las bases de datos NoSQL, que ofrecen una mayor flexibilidad y escalabilidad para ciertos tipos de aplicaciones. Sin embargo, en el contexto de las aplicaciones transaccionales y analíticas tradicionales, los datos suelen ser estructurados y de un volumen manejable, por lo que las bases de datos relacionales siguen siendo una opción popular y ampliamente utilizada en este contexto. |
2.2. Almacenes de datos relacionales
Los datos de las fuentes de datos operacionales se copian en un almacén de datos (data warehouse), lo que permite a los usuarios ejecutar consultas e informes contra el almacén de datos en lugar de hacerlo directamente sobre las fuentes de datos. De esta manera, no se sobrecarga los sistemas que albergan las fuentes originales, evitando la ralentización de las aplicaciones para los usuarios finales. Los almacenes de datos relacionales (RDWs) también centralizan datos de múltiples aplicaciones para mejorar la generación de informes.
2.3. Data lakes
Puedes pensar en un data lake como un sistema de archivos vitaminado, no muy diferente al sistema de archivos en tu computadora portátil. Un data lake es simplemente un almacenamiento; a diferencia de un almacén de datos relacional, no tiene un motor de cómputo asociado. Otra diferencia es que, mientras los RDWs utilizan almacenamiento relacional, los data lakes emplean almacenamiento de objetos, que no requiere que los datos estén estructurados en filas y columnas.
La tecnología de almacenamiento en data lakes comenzó con el Apache Hadoop Distributed File System (HDFS), una tecnología gratuita y de código abierto que estaba casi exclusivamente en instalaciones locales y que fue muy popular a principios de la década de 2010. HDFS es un sistema de almacenamiento distribuido escalable y tolerante a fallos diseñado para ejecutarse en hardware estándar. Es un componente central del ecosistema Apache Hadoop.
Los datos en un data lake se almacenan en su formato natural (o bruto), lo que significa que pueden ir desde el sistema fuente al data lake sin ser transformados a otro formato. Estos archivos pueden contener datos estructurados (como datos de bases de datos relacionales), semi-estructurados (como archivos CSV, registros, XML o JSON) o no estructurados (como correos electrónicos, documentos y PDFs). También pueden incluir datos binarios (como imágenes, audio y video).
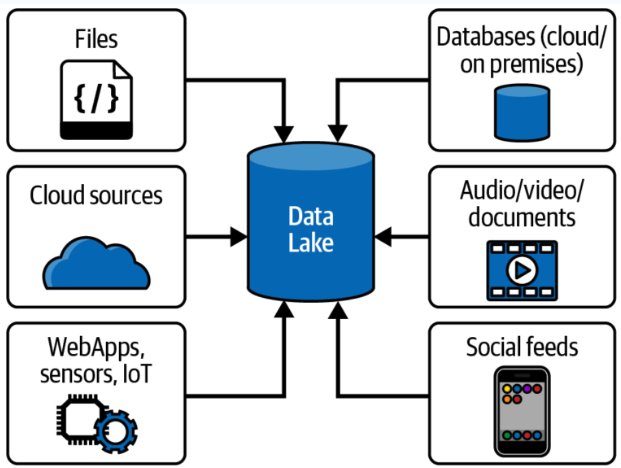
Los data lakes surgieron como la solución a todos los problemas asociados con los almacenes de datos relacionales, como el alto costo, la escalabilidad limitada, el bajo rendimiento, la sobrecarga en la preparación de datos y el soporte limitado para tipos de datos complejos. Empresas que vendían Hadoop y data lakes, como Cloudera, Hortonworks y MapR, los promocionaron como si estuvieran llenos de unicornios y arcoíris que copiarían y limpiarían datos, haciéndolos disponibles para los usuarios finales con facilidad mágica. Aseguraban que los data lakes podrían reemplazar completamente a los almacenes de datos relacionales, adoptando un enfoque de "una tecnología para hacerlo todo".
El problema era que consultar los data lakes no era tan sencillo: requería habilidades bastante avanzadas. El personal de TI les decía a los usuarios finales: "Hemos copiado todos los datos que necesitas en este data lake. Solo abre un cuaderno de Jupyter y usa Hive y Python para construir tus informes con los archivos en estas carpetas."
Además, los data lakes no contaban con algunas de las características que la gente valoraba en los almacenes de datos, como el soporte de transacciones, la aplicación de esquemas y las trazas de auditoría. Esto llevó a que dos de los tres principales proveedores de data lakes, Hortonworks y MapR, cerraran sus puertas.
Pero el data lake no desapareció. En lugar de eso, su propósito se transformó en uno diferente, pero muy útil: la preparación y el almacenamiento temporal de datos.
2.4. Almacenes de datos modernos
Los data lakes no lograron reemplazar completamente a los almacenes de datos relacionales, pero sí ofrecen beneficios para la preparación y el almacenamiento temporal de datos. ¿Por qué no aprovechar las ventajas de ambos?
Alrededor de 2011, muchas empresas comenzaron a construir arquitecturas que combinaban data lakes con almacenes de datos relacionales, formando la arquitectura de datos que ahora llamamos el almacén de datos moderno (MDW, por sus siglas en inglés). Esta combinación permite aprovechar los beneficios de ambos enfoques:
-
Almacenes de datos relacionales: Proporcionan un marco estructurado para la consulta y análisis de datos organizados, con soporte para transacciones, aplicación de esquemas y control de calidad.
-
Data lakes: Ofrecen flexibilidad para almacenar grandes volúmenes de datos en su formato original, permitiendo la ingesta de datos no estructurados y semi-estructurados, y facilitando la preparación y el procesamiento previo de los datos.
Al integrar ambos, el almacén de datos moderno (MDW) combina la capacidad de los data lakes para manejar datos en su formato bruto y la robustez de los almacenes de datos relacionales para realizar análisis complejos y mantener la calidad y la integridad de los datos. Esto permite una solución más completa y flexible para el almacenamiento y análisis de datos.

2.5. Fábricas de datos
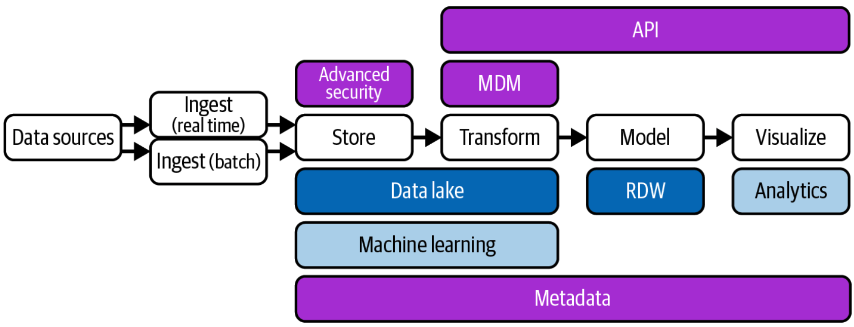
Las fábricas de datos comenzaron a aparecer alrededor de 2016. La arquitectura de una fábrica de datos se puede considerar como una evolución de la arquitectura del almacén de datos moderno, con tecnología adicional para captar más datos, asegurar su integridad y hacerlos disponibles de manera más eficiente.
Una fábrica de datos integra y orquesta datos a través de múltiples entornos y plataformas, proporcionando una capa unificada de gestión de datos que abarca tanto datos estructurados como no estructurados. Esta arquitectura permite una mejor visibilidad, gobernanza y accesibilidad de los datos a lo largo de toda la organización, facilitando la integración de datos provenientes de diversas fuentes y la aplicación de políticas de seguridad y privacidad en un entorno cada vez más complejo.
2.6. Data lakehouses
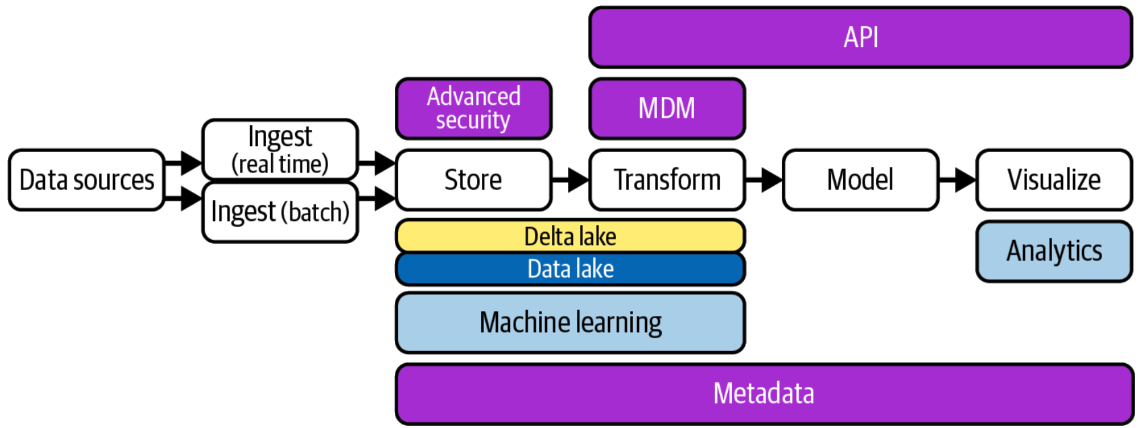
El término data lakehouse es una combinación de data lake y data warehouse. Las arquitecturas de data lakehouse se hicieron populares alrededor de 2020, cuando la empresa Databricks comenzó a utilizar este término. El concepto de un lakehouse es eliminar el almacén de datos relacional y usar solo un repositorio, un data lake, en la arquitectura de datos. Todos los tipos de datos—estructurados, semi-estructurados y no estructurados—se ingieren en el data lake, y todas las consultas e informes se realizan directamente desde el data lake.
Pero si dijimos que los data lakes adoptaron este mismo enfoque cuando aparecieron por primera vez, ¡y fracasaron estrepitosamente! ¿Qué ha cambiado? La respuesta es una capa de software de almacenamiento transaccional llamada Delta Lake que se ejecuta sobre un data lake existente y hace que funcione de manera más parecida a una base de datos relacional. Las opciones de código abierto que compiten en esta capa incluyen Delta Lake, Apache Iceberg y Apache Hudi.
2.7. Data mesh
Las arquitecturas de almacén de datos moderno, fábrica de datos y data lakehouse implican la centralización de datos: copiar los datos operacionales en una ubicación centralizada propiedad de TI bajo una arquitectura que TI controla, donde TI luego crea los datos analíticos (lado izquierdo de la figura). Este enfoque centralizado presenta tres desafíos principales: propiedad de los datos, calidad de los datos y escalabilidad organizacional/técnica. El objetivo del data mesh es resolver estos desafíos.
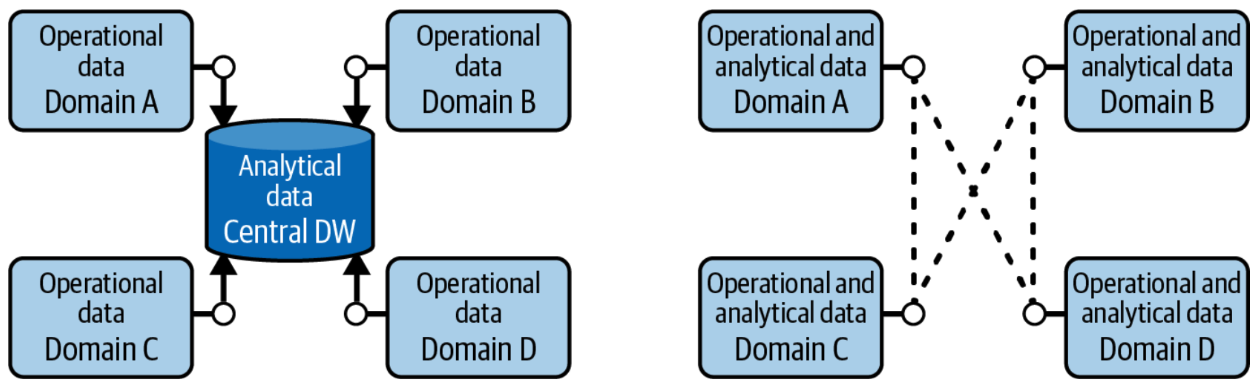
En un data mesh, los datos se mantienen dentro de varios dominios dentro de una empresa, como fabricación, ventas y proveedores (lado derecho de la figura). Cada dominio cuenta con su propio equipo de TI que es responsable de sus datos, los limpia, crea los datos analíticos y los pone a disposición. Cada dominio también tiene su propia infraestructura de computación y almacenamiento. Esto resulta en una arquitectura descentralizada donde los datos, las personas y la infraestructura se expanden—cuantos más dominios tienes, más personas e infraestructura obtienes. El sistema puede manejar más datos, y TI deja de ser un cuello de botella.
Es importante entender que el data mesh es un concepto, no una tecnología. No existe un "data mesh en una caja" que puedas comprar.
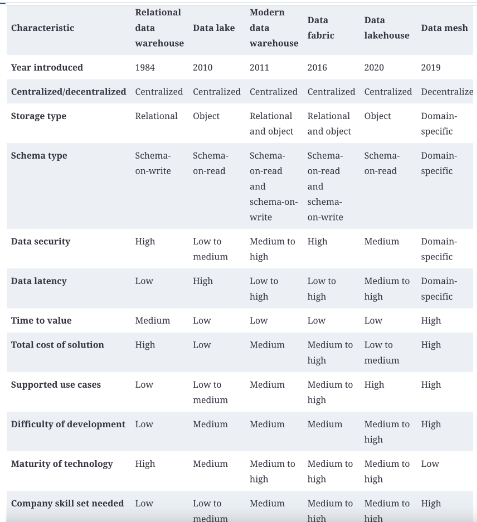
2.8. Resumen comparativo
A continuación, se presenta un resumen comparativo de las arquitecturas de datos mencionadas:
3. Sesión de diseño de la arquitectura de datos
Una sesión de diseño de arquitectura (ADS, por sus siglas en inglés) es una discusión estructurada con partes interesadas tanto empresariales como técnicas, guiada por expertos técnicos y enfocada en definir y planificar el diseño de alto nivel de una solución para recopilar datos para oportunidades empresariales específicas. La ADS debe producir dos entregables:
-
Una arquitectura (o "plano") que pueda servir como punto de partida para la solución de datos.
-
Un plan de acción de alto nivel, que puede incluir demostraciones posteriores, pruebas de concepto y discusiones sobre productos.
Una ADS no es un taller técnico, una capacitación técnica, una demostración técnica ni una sesión de requisitos de bajo nivel.
A continuación se muestra un ejemplo de agenda para una sesión de diseño de arquitectura de datos:

4. Almacenes de datos relacionales
Un almacén de datos relacional (RDW, por sus siglas en inglés) es un sistema donde se almacenan y gestionan de manera centralizada grandes volúmenes de datos estructurados, copiados de múltiples fuentes de datos para su uso en informes de análisis histórico y de tendencias, con el fin de que una organización pueda tomar decisiones de negocio más informadas. Se llama relacional porque se basa en el modelo relacional, un enfoque ampliamente utilizado para la representación y organización de datos en bases de datos. Se denomina almacén de datos porque recopila, almacena y gestiona volúmenes masivos de datos estructurados provenientes de diversas fuentes, como bases de datos transaccionales, sistemas de aplicaciones y fuentes de datos externas.
4.1. Objetivos de un almacén de datos (relacional)
-
Reducir la carga en el sistema de producción: Minimizar el impacto en los sistemas operacionales al centralizar el análisis en el almacén de datos.
-
Optimizar el acceso de lectura: Mejorar el rendimiento en la consulta y generación de informes.
-
Integrar múltiples fuentes de datos: Consolidar datos de diversas fuentes para una visión unificada.
-
Generar informes históricos precisos: Proporcionar informes detallados sobre tendencias y datos históricos.
-
Reestructurar y renombrar tablas: Adaptar la estructura de datos para facilitar el análisis.
-
Proteger contra actualizaciones de aplicaciones: Asegurar que los cambios en las aplicaciones no afecten los informes.
-
Reducir preocupaciones de seguridad: Implementar medidas para proteger los datos sensibles.
-
Mantener datos históricos: Conservar datos a lo largo del tiempo para análisis en profundidad.
-
Gestión de datos maestros (MDM): Garantizar una única fuente de verdad para los datos clave.
-
Mejorar la calidad de los datos: Corregir problemas en los sistemas de origen para asegurar datos precisos y completos.
-
Eliminar la participación de TI en la creación de informes: Permitir a los usuarios finales crear informes de manera autónoma sin depender de TI.
4.2. Desafíos de un almacén de datos (relacional)
-
Complejidad: La implementación y gestión de un RDW puede ser complicada debido a la necesidad de integrar y estructurar grandes volúmenes de datos.
-
Altos costos: Los costos de licencias, hardware, y mantenimiento pueden ser significativos.
-
Desafíos en la integración de datos: Consolidar datos de múltiples fuentes puede ser complicado y requerir soluciones personalizadas.
-
Transformación de datos que consume tiempo: Los procesos de limpieza y transformación de datos pueden ser largos y laboriosos.
-
Latencia de datos: Los datos en el almacén de datos pueden no estar actualizados con los cambios más recientes en las bases de datos de origen.
-
Ventana de mantenimiento: Las actualizaciones y el mantenimiento del sistema pueden requerir tiempos de inactividad programados.
-
Flexibilidad limitada: Los RDWs están diseñados para soportar tipos específicos de análisis, lo que puede limitar su flexibilidad para otros tipos de procesamiento o análisis de datos.
-
Preocupaciones de seguridad y privacidad: Almacenar grandes cantidades de datos sensibles en una ubicación centralizada puede aumentar el riesgo de brechas de seguridad y violaciones de privacidad.
4.3. Población de un almacén de datos
Una de las tareas más importantes en la implementación de un almacén de datos es la población inicial del almacén con datos de las fuentes de datos operacionales. La población inicial implica extraer, transformar y cargar (ETL) los datos desde las fuentes de datos operacionales al almacén de datos. No obstante, los procesos de ETL también están presentes en la operación continua del almacén de datos, ya que los datos deben actualizarse regularmente para mantener la información actualizada. La población inicial y la operación continua del almacén de datos son procesos críticos que requieren una planificación cuidadosa y una ejecución precisa. A continuación se describen los pasos típicos en el proceso de población de un almacén de datos:
-
Métodos de Extracción
-
Extracción Completa: Se extrae todo el conjunto de datos desde el sistema de origen a cada vez, lo que puede ser costoso y consumir mucho tiempo, pero asegura que se capture toda la información.
-
Extracción Incremental: Solo se extraen los datos que han cambiado desde la última extracción. Esto es más eficiente en términos de tiempo y recursos.
-
-
Cómo determinar los datos que han cambiado desde la última extracción
-
Timestamps: Algunas tablas en los sistemas operacionales tienen columnas de timestamp que registran la fecha y hora de la última modificación de una fila. Esta información puede usarse para identificar los datos que han cambiado.
-
Captura de Datos de Cambio (CDC): La mayoría de las bases de datos relacionales soportan CDC, que graba los INSERTs, UPDATEs y DELETEs aplicados a las tablas de la base de datos, proporcionando un registro de los cambios realizados.
-
Particionamiento: Las tablas de origen se particionan según una clave de fecha, facilitando la identificación de datos nuevos. Esto permite extraer solo las particiones que han cambiado desde la última extracción.
-
Triggers de Base de Datos: Se utilizan triggers para rastrear cambios mediante la captura de INSERTs, UPDATEs y DELETEs en las tablas de origen.
-
Sentencia MERGE: La opción menos preferida es realizar una extracción completa desde el sistema de origen a un área de staging en el almacén de datos, y luego comparar esta tabla con una extracción completa anterior utilizando una declaración MERGE para identificar los datos que han cambiado. Este método puede ser menos eficiente y más laborioso.
-
5. Data lakes
El big data comenzó a aparecer en volúmenes sin precedentes a principios de la década de 2010 debido al aumento de fuentes que generan datos semiestructurados y no estructurados, como sensores, videos y redes sociales. Los data lakes pueden manejar fácilmente datos semiestructurados y no estructurados y gestionar datos que se ingieren con frecuencia.
El término "data lake" es una metáfora para describir el concepto de almacenar grandes cantidades de datos en su formato natural. Así como un lago contiene agua sin alterar la naturaleza del agua, un data lake almacena datos sin necesidad de estructurarlos o procesarlos primero.
Los data lakes son espacios de almacenamiento distribuido muy utilizados hoy en día para crear grandes repositorios de datos corporativos heterogéneos en la nube. A diferencia de un almacén de datos (data warehouse), un data lake no cuenta con un motor de base de datos subyacente ni existe un modelo relacional de los datos.
5.1. La importancia de los datos semmi-estructurados y no estructurados
Veamos este caso de uso: Unos analistas de una gran cadena de tiendas querían captar datos de Twitter para entender qué pensaban los clientes sobre sus tiendas. Sabían que los clientes podrían dudar en presentar quejas a los empleados de la tienda, pero estarían dispuestos a publicarlas en Twitter. Con la ingesta de datos de Twitter en un data lake y la evaluación del sentimiento de los comentarios de los clientes, categorizándolos como positivos, neutros o negativos, los analistas pudieron identificar problemas en las tiendas y tomar medidas correctivas. Al revisar los comentarios negativos, encontraron un número inusualmente alto de quejas sobre los probadores: eran demasiado pequeños, estaban demasiado llenos y no ofrecían suficiente privacidad. Como experimento, la empresa decidió remodelar los probadores en una tienda. Un mes después de la remodelación, los analistas encontraron un gran número de comentarios positivos sobre los probadores en esa tienda, junto con un aumento del 7% en las ventas. Esto llevó a la empresa a remodelar los probadores en todas sus tiendas, resultando en un aumento del 6% en las ventas a nivel nacional y millones de dólares adicionales en ganancias. ¡Todo gracias a un data lake!
|
Tip
|
Los data lakes son especialmente útiles para almacenar y analizar datos semiestructurados y no estructurados, como correos electrónicos, documentos, imágenes, videos, registros de transacciones, datos de sensores y datos de redes sociales. Estos datos pueden ser difíciles de manejar con un enfoque tradicional de bases de datos relacionales, pero los data lakes permiten almacenarlos y procesarlos de manera eficiente. Si te parece interesante este tema, puedes profundizar en este tutorial sobre análisis de sentimientos con servicios de Azure AI. |
5.2. Data lake vs Data Swamp
Un data lake generalmente no impone una estructura específica a los datos que ingiere. De hecho, esta es una de sus características clave (ver Schema on write vs. schema on read en la sección Bases de datos relacionales). Esto es diferente de una base de datos tradicional o un almacén de datos, que requiere que los datos estén estructurados o modelados previamente. Sin embargo, para que los datos sean utilizables y evitar que el data lake se convierta en un “pantano de datos” (una colección desorganizada e inmanejable de datos), es importante aplicar algunas prácticas de organización y gobernanza. Esta sección presenta algunas buenas prácticas para empezar:
-
Establecer un catálogo de datos: Implementar un catálogo de datos para registrar qué datos están disponibles, de dónde provienen, y cómo se deben utilizar. Esto facilita la búsqueda y gestión de datos dentro del data lake.
-
Aplicar metadatos: Utilizar metadatos para describir el contenido, el formato y la estructura de los datos. Los metadatos ayudan a los usuarios a entender el contexto de los datos y a encontrar información relevante más fácilmente.
-
Implementar gobernanza de datos: Definir y aplicar políticas de gobernanza de datos para asegurar que los datos sean precisos, confiables y se manejen de acuerdo con las normativas y estándares de seguridad.
-
Definir estrategias de seguridad: Implementar controles de acceso adecuados y cifrado para proteger los datos sensibles y garantizar que solo los usuarios autorizados puedan acceder a la información.
-
Realizar limpieza y mantenimiento de forma regular: Establecer procesos para la limpieza y el mantenimiento regular de los datos para evitar que el data lake se llene de datos obsoletos o irrelevantes.
-
Facilitar el acceso y la integración: Proporcionar herramientas y interfaces que permitan a los usuarios acceder a los datos de manera eficiente y integrarlos con otras fuentes y sistemas según sea necesario.
-
Monitorizar el rendimiento: Supervisar el rendimiento del data lake para asegurar que pueda manejar el volumen y la variedad de datos sin afectar negativamente a la velocidad o la eficiencia del sistema.
Estas prácticas ayudan a asegurar que el data lake se mantenga organizado y útil, evitando que se convierta en una acumulación desordenada de datos que sea difícil de gestionar y utilizar.
5.3. Creando un data lake
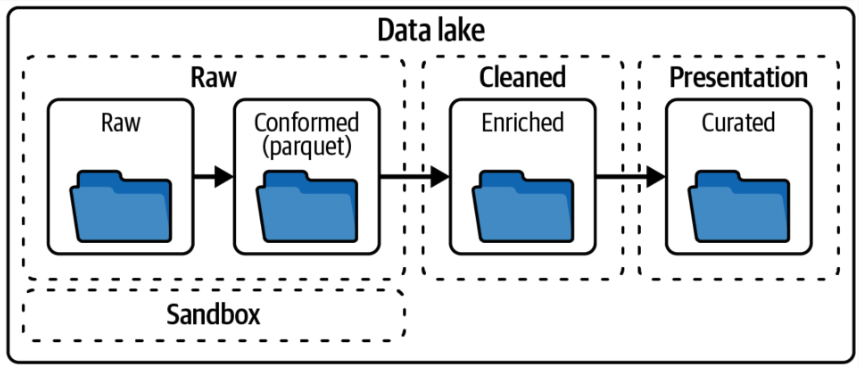
5.3.1. Dividir el data lake en varias capas (también llamadas zonas)
Las zonas corresponden a niveles crecientes de calidad de datos:
-
Capa Raw (Cruda): Aquí se almacenan los eventos en su formato original para referencia histórica. Estos datos suelen guardarse de forma inmutable, es decir, no se modifican una vez que se han almacenado. Como características, los datos se mantienen tal como fueron capturados, en formatos diversos como CSV, JSON, o Parquet.
-
Capa Conformed (Conformada): En esta capa todos los tipos de archivos de la capa cruda se convierten a un formato común, generalmente Parquet. Esto facilita el procesamiento eficiente de big data. Como características, la conversión a un formato único permite la estandarización y preparación para el siguiente nivel de calidad de datos.
-
Capa Cleansed (Limpiada): En esta capa los eventos crudos se transforman. Los datos se limpian, integran y consolidan para crear conjuntos de datos directamente utilizables. Como características, se corrigen inconsistencias (como errores en nombres de ítems, cantidades erróneas y marcas de tiempo faltantes) y se transforman en un esquema común (por ejemplo, convenios de nombres, formatos de tiempo, o sistemas de ID de tienda comunes).
-
Capa Presentation (Presentación): Se aplica la lógica de negocio a los datos limpios para producir datos listos para ser consumidos por usuarios finales o aplicaciones. Esta capa suele presentar los datos en un formato fácil de entender y utilizar. Como características, la transformación puede incluir agregaciones, resúmenes, o la disposición de los archivos en un formato específico para su uso en herramientas de informes.
-
Capa Sandbox (Zona de Experimentación): Esta capa opcional se utiliza para "jugar" o experimentar. Generalmente, es utilizada por científicos de datos y es una copia de la capa raw donde los datos no solo se pueden leer, sino también modificar. Como características, puede haber múltiples capas sandbox, también conocidas como capas de exploración, desarrollo o espacio de trabajo de ciencia de datos.
Cada una de estas capas permite gestionar los datos de manera que se pueda mejorar su calidad y utilidad a medida que se avanza a través del proceso de análisis y preparación.
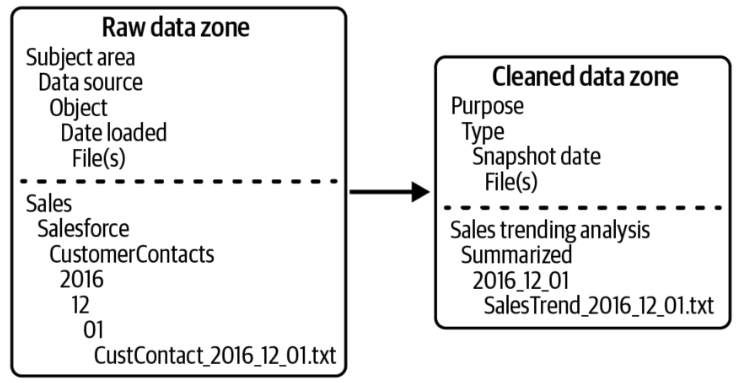
5.3.2. Crear una estructura de carpetas lógica
También es útil organizar los datos en el data lake en una estructura de carpetas lógica que refleje las diferentes capas y zonas de calidad de datos por las que van pasando los datos a medida que pasan por diferentes niveles de procesamiento. Esto facilita la gestión y el acceso a los datos, así como la implementación de políticas de gobernanza y seguridad. A continuación se muestra un ejemplo de una estructura de carpetas para un data lake organizada por capas incluyendo las fechas para una mejor organización y gestión de los datos.
/data_lake
│
├── /raw
│ ├── /csv
│ │ ├── /2024
│ │ └── /2023
│ ├── /json
│ │ ├── /2024
│ │ └── /2023
│ ├── /parquet
│ │ ├── /2024
│ │ └── /2023
│ └── /logs
│ ├── /2024
│ └── /2023
│
├── /conformed
│ ├── /parquet
│ │ ├── /2024
│ │ └── /2023
│ ├── /csv
│ │ ├── /2024
│ │ └── /2023
│ └── /json
│ ├── /2024
│ └── /2023
│
├── /cleansed
│ ├── /standardized
│ │ ├── /2024
│ │ └── /2023
│ ├── /integrated
│ │ ├── /2024
│ │ └── /2023
│ └── /consolidated
│ ├── /2024
│ └── /2023
│
├── /presentation
│ ├── /reports
│ │ ├── /2024
│ │ └── /2023
│ ├── /dashboards
│ │ ├── /2024
│ │ └── /2023
│ └── /summaries
│ ├── /2024
│ └── /2023
│
└── /sandbox
├── /exploration
│ ├── /2024
│ └── /2023
├── /development
│ ├── /2024
│ └── /2023
└── /data_science
├── /2024
└── /20235.4. Catálogo de Datos
Un catálogo de datos es un repositorio centralizado, típicamente alojado en la nube, que almacena y organiza metadatos sobre todas las fuentes de datos, tablas, esquemas, columnas y otros activos de datos de una organización, como informes y dashboards, procesos ETL y scripts SQL. Funciona como una única fuente de verdad para que los usuarios descubran, comprendan y gestionen datos almacenados en bases de datos de aplicaciones, lagos de datos, almacenes de datos, data marts y cualquier otra forma de almacenamiento de datos.
Un catálogo de datos típicamente incluye la siguiente información sobre cada activo de datos:
-
Información sobre la fuente: Ubicación, tipo y detalles de conexión.
-
Si está en un RDW: Información sobre tablas y esquemas (estructura, relaciones y organización) y columnas (tipos de datos, formatos, descripciones y relaciones entre columnas).
-
Si está en un almacenamiento de objetos como un data lake: Propiedades de archivos (almacenamiento, nombre de carpeta, nombre de archivo).
-
-
Linaje de datos: Cómo llegó el dato desde su origen, incluyendo información sobre cualquier transformación, agregación e integración que haya sufrido el dato.
-
Detalles de gobernanza y cumplimiento de datos: Calidad de los datos, propiedad y políticas.
-
Herramientas de búsqueda y descubrimiento: Herramientas para que los usuarios busquen, filtren y encuentren datos relevantes.
|
Note
|
Una herramienta destacada en este ámbito es OpenMetadata. |
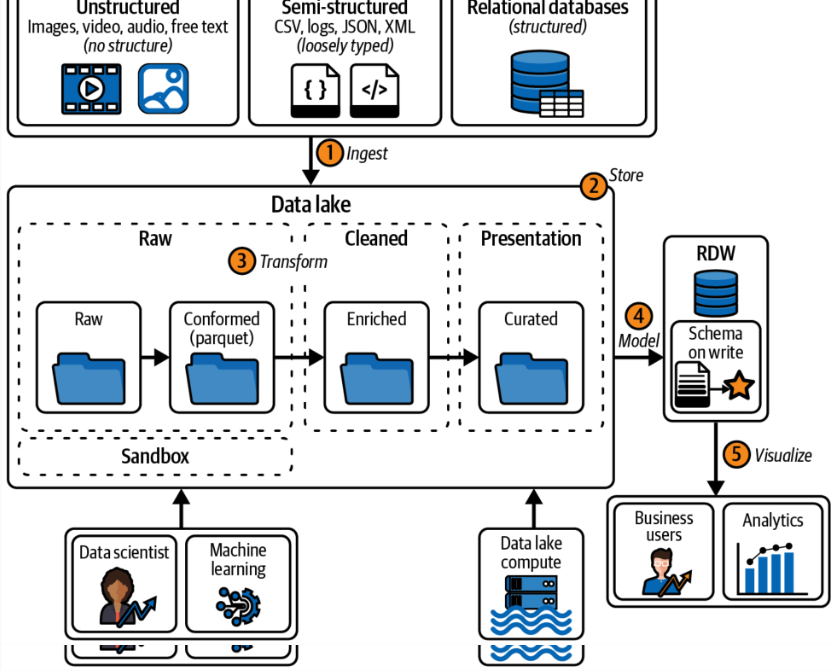
6. El almacén de datos moderno
Imaginemos un supermercado en la ciudad que cambia de bases de datos tradicionales a un almacén de datos moderno (MDW). Ahora, los gerentes pueden acceder a datos de inventario en tiempo real, predecir tendencias de compra y optimizar la experiencia de compra para sus clientes. Ese es el poder de un MDW. Combina lo mejor de ambos mundos: la estructura de los RDWs y la flexibilidad de los lagos de datos.
En un MDW, el data lake se utiliza para la preparación y el almacenamiento de datos, mientras que el RDW se encarga de la presentación y la seguridad.
7. Fábrica de datos
La arquitectura de una fábrica de datos es una evolución de la arquitectura del almacén de datos moderno (MDW): una capa avanzada construida sobre el MDW para mejorar el acceso a los datos, la seguridad, la capacidad de descubrimiento y la disponibilidad.
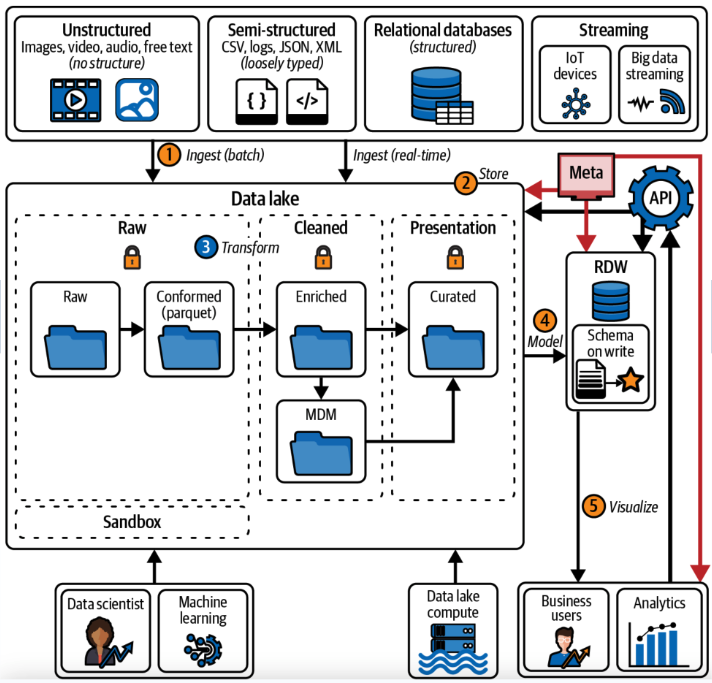
Como características, destacar las siguientes:
-
Políticas de Acceso a Datos: Las políticas de acceso a datos son clave para la gobernanza de datos. Comprenden un conjunto de directrices, reglas y procedimientos que controlan quién tiene acceso a qué información, cómo se puede utilizar esa información y cuándo se puede conceder o denegar el acceso dentro de una organización. Ayudan a garantizar la seguridad, privacidad e integridad de los datos sensibles, así como el cumplimiento de leyes y regulaciones.
-
Catálogo de Metadatos: Las arquitecturas de fábrica de datos incluyen un catálogo de metadatos: un repositorio que almacena información sobre los activos de datos, incluyendo su estructura, relaciones y características. Proporciona una manera centralizada y organizada de gestionar y descubrir datos, facilitando a los usuarios encontrar y entender los datos que necesitan. Por ejemplo, si un usuario busca en el catálogo de metadatos "cliente", los resultados incluirán archivos, tablas de bases de datos, informes o paneles de control que contengan datos de clientes. Hacer posible ver qué ingestión y reportes ya se han realizado ayuda a evitar esfuerzos duplicados. Una parte importante del catálogo es el linaje de datos, un registro de la historia de cualquier pieza de datos, incluyendo de dónde provino, cómo fue transformada y dónde está almacenada.
-
Gestión de datos maestros (MDM): La MDM es el proceso de recolectar, consolidar y mantener datos consistentes y precisos de diversas fuentes dentro de una empresa para crear una fuente única y autorizada para datos maestros. La MDM ayuda a las empresas a tomar decisiones informadas y evitar problemas relacionados con los datos, como registros duplicados, inconsistencias e información incorrecta.
-
Virtualización de datos: La virtualización de datos es una arquitectura de software que permite a las aplicaciones y a los usuarios finales acceder a datos de múltiples fuentes como si estuvieran almacenados en una sola ubicación.
-
Procesamiento en tiempo real: Se refiere al procesamiento de datos y la producción de resultados inmediatos tan pronto como esos datos estén disponibles, sin retrasos notables.
-
APIs: Las APIs proporcionan datos de una manera estandarizada desde una variedad de fuentes, como un data lake o un RDW, sin compartir los detalles específicos de dónde está ubicado el dato.
8. Data lakehouse
La idea detrás de un data lakehouse es simplificar las cosas al utilizar solo un data lake para almacenar todos tus datos, en lugar de tener también un data warehouse relacional separado. Para lograr esto, el data lake necesita más funcionalidades para reemplazar las características de un RDW. Aquí es donde entra en juego Delta Lake de Databricks.
Delta Lake añade una capa de almacenamiento transaccional sobre el data lake, permitiendo que este funcione más como un RDW al proporcionar:
-
Transacciones ACID: Garantiza que las operaciones de lectura y escritura sean consistentes, seguras y confiables, similares a las que ofrece un RDW.
-
Esquema predefinido: Permite imponer un esquema en los datos, asegurando que los datos escritos cumplan con las especificaciones del esquema definido, lo que ayuda a mantener la calidad de los datos.
-
Versionado de datos: Facilita el seguimiento de cambios en los datos y la capacidad de revertir a versiones anteriores, proporcionando una capa adicional de seguridad y control.
-
Optimización de consultas: Usa técnicas de optimización y almacenamiento en formato de columna (como Parquet) para mejorar el rendimiento de las consultas y la eficiencia del almacenamiento.
Con Delta Lake, el data lakehouse puede ofrecer las capacidades analíticas avanzadas y el rendimiento de un RDW, mientras mantiene la flexibilidad y escalabilidad de un data lake.
8.1. Delta Lake (Mejorando los Data Lakes con Capacidades Transaccionales)
Delta Lake es una capa de almacenamiento transaccional diseñada para ejecutarse sobre un data lake existente, aportando características avanzadas que normalmente se asocian con los almacenes de datos relacionales (RDW) al mundo de los data lakes. A diferencia de un RDW, Delta Lake no proporciona almacenamiento en sí; en cambio, mejora la funcionalidad del data lake subyacente al introducir características que optimizan la confiabilidad, seguridad y rendimiento de los datos.
-
Funcionamiento: En su núcleo, Delta Lake transforma la gestión de datos dentro de un data lake mediante el uso de un formato especializado. Cuando los datos se almacenan utilizando Delta Lake, se organizan en archivos Parquet, un formato de almacenamiento columnar de código abierto optimizado para el procesamiento de grandes volúmenes de datos. Además, Delta Lake mantiene un registro de transacciones que rastrea todos los cambios realizados en los datos. Este registro asegura que todas las modificaciones se registren de manera precisa, lo que facilita operaciones de datos confiables y la recuperación de datos.
-
Beneficios:
-
Integridad transaccional: Delta Lake soporta transacciones ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad), lo que asegura la consistencia y confiabilidad de los datos incluso frente a operaciones concurrentes de lectura y escritura. Esta capacidad mitiga problemas como la corrupción o pérdida de datos, comunes en los data lakes tradicionales.
-
Cumplimiento y evolución del esquema: Delta Lake permite el cumplimiento del esquema, lo que significa que los datos deben adherirse a una estructura predefinida antes de ser escritos. También soporta la evolución del esquema, acomodando cambios en la estructura de los datos con el tiempo sin interrumpir las operaciones en curso.
-
Viaje en el tiempo: Delta Lake proporciona una característica conocida como "viaje en el tiempo", que permite a los usuarios consultar versiones históricas de los datos. Esto es particularmente útil para auditorías, depuración o recuperación de cambios no deseados.
-
Calidad de datos: Al mantener registros detallados de los cambios en los datos, Delta Lake ayuda a garantizar una alta calidad de los datos. Los usuarios pueden rastrear y gestionar anomalías o inconsistencias en los datos de manera efectiva.
-
-
Alternativas: Aunque Delta Lake es una solución prominente, no es la única opción disponible para mejorar los data lakes con capacidades transaccionales. Dos alternativas populares son:
-
Apache Iceberg: Iceberg es un formato de tabla de código abierto que ofrece características similares a Delta Lake, incluyendo soporte para transacciones ACID, evolución del esquema y viaje en el tiempo. Está diseñado para manejar conjuntos de datos a gran escala y está optimizado para consultas de alto rendimiento.
-
Apache Hudi: Hudi es otro marco de gestión de datos de código abierto que ofrece características como actualizaciones incrementales y versionado de datos. Es especialmente adecuado para el procesamiento y análisis de datos en tiempo real.
-
Cada una de estas herramientas (Delta Lake, Apache Iceberg y Apache Hudi) ofrece ventajas únicas y puede ser elegida en función del caso de uso y requisitos. Juntas, representan una evolución significativa en la tecnología de data lakes, combinando la flexibilidad de los data lakes con las capacidades robustas tradicionalmente asociadas con los RDWs.
8.2. Características de Delta Lake para Data Lakes
Delta Lake introduce una serie de características inspiradas en los almacenes de datos relacionales (RDW) para mejorar la funcionalidad y el manejo de datos en los data lakes. A continuación, se detallan algunas de las principales características que ofrece Delta Lake:
-
Soporte para comandos DML: Delta Lake admite comandos DML (Data Manipulation Language), como INSERT, DELETE, UPDATE y MERGE. Tradicionalmente, actualizar datos en un data lake implica leer el archivo completo, realizar las actualizaciones necesarias y volver a escribir el archivo completo, un proceso que puede ser lento, especialmente para archivos grandes. Delta Lake aborda este problema dividiendo la tabla en varios archivos más pequeños para facilitar su gestión, creando lo que se conoce como una Delta Table. Cuando se ejecuta una instrucción UPDATE, Delta Lake identifica y selecciona todos los archivos que contienen datos que coinciden con el predicado de la consulta y que, por lo tanto, necesitan ser actualizados. Luego, lee cada archivo coincidente en memoria, actualiza las filas relevantes y escribe el resultado en nuevos archivos de datos.
-
Transacciones ACID: Delta Lake soporta transacciones ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad), aunque está limitado a una sola Delta Table. Esto asegura que las operaciones realizadas en la tabla sean consistentes y seguras, incluso cuando se realizan múltiples operaciones simultáneamente.
-
Viaje en el tiempo: Una característica destacada de Delta Lake es el "viaje en el tiempo", que permite a los usuarios consultar datos almacenados en Delta Tables como existían en un momento específico del pasado. Esta capacidad permite a los usuarios ver y acceder a versiones anteriores de los datos y, si es necesario, revertir los datos a una versión previa.
-
Procesamiento por lotes y Streaming en tiempo Real: Delta Lake permite realizar procesamiento por lotes y streaming en tiempo real sobre los mismos datos en una Delta Table. Esto ofrece flexibilidad para trabajar con datos históricos y en tiempo real sin necesidad de gestionar diferentes conjuntos de datos o sistemas de procesamiento.
-
Aplicación y cumplimiento del esquema: La aplicación del esquema es otra característica importante de Delta Lake. Permite especificar el esquema esperado para los datos en una Delta Table y aplicar reglas como restricciones de nulidad, restricciones de tipo de datos y restricciones de unicidad. Esto asegura que los datos cumplan con los requisitos estructurales definidos y ayuda a mantener la integridad de los datos.
Estas características permiten que Delta Lake combine la flexibilidad de los data lakes con capacidades avanzadas de gestión de datos, ofreciendo una solución robusta para la manipulación y el análisis de grandes volúmenes de datos.
8.3. Inconvenientes de Delta Lake
A pesar de las avanzadas características que Delta Lake añade a los data lakes, hay algunas áreas en las que los almacenes de datos relacionales (RDW) todavía pueden superar a Delta Lake. Aquí se detallan algunas de las principales diferencias:
-
Velocidad de Consultas: Las consultas en bases de datos relacionales suelen ser más rápidas en comparación con las consultas realizadas en un Delta Lake. Esto se debe en parte a que muchos RDWs utilizan tecnología de procesamiento masivo en paralelo (MPP), que distribuye las consultas a través de múltiples nodos para procesarlas simultáneamente. Esto permite una ejecución más rápida y eficiente de consultas complejas y de grandes volúmenes de datos. Delta Lake, por otro lado, está diseñado para ofrecer flexibilidad y manejo avanzado de datos, pero no puede igualar la velocidad de procesamiento de consultas de un RDW con MPP.
-
Seguridad: Delta Lake, aunque mejora las capacidades de los data lakes tradicionales, todavía carece de algunas de las características de seguridad comunes en los RDWs, como:
-
Seguridad a Nivel de Fila (Row-Level Security): Los RDWs a menudo permiten definir reglas de acceso a nivel de fila, lo que significa que diferentes usuarios pueden ver diferentes subconjuntos de los datos basados en sus credenciales o roles. Delta Lake no ofrece esta funcionalidad de forma nativa. Sin embargo, esta funcionalidad puede ser implementada a través de herramientas de gestión de acceso a datos como Apache Ranger. También se puede lograr mediante la implementación de lógica de seguridad en la capa de aplicación.
-
Seguridad a Nivel de Columna (Column-Level Security): Similar a la seguridad a nivel de fila, la seguridad a nivel de columna permite controlar el acceso a columnas específicas de una tabla. Los RDWs pueden ofrecer esta funcionalidad para proteger información sensible, una característica que Delta Lake no proporciona por defecto. Sin embargo, al igual que con la seguridad a nivel de fila, esta funcionalidad puede ser implementada a través de herramientas de gestión de acceso a datos, como Apache Ranger. También se puede lograr mediante la implementación de lógica de seguridad en la capa de aplicación.
-
Cifrado de datos en reposo (Data-at-Rest Encryption): Los RDWs suelen incorporar cifrado de datos en reposo para proteger la información almacenada contra accesos no autorizados. Aunque Delta Lake puede utilizar encriptación a nivel de almacenamiento, la encriptación específica y la implementación de encriptación a nivel de archivo pueden no ser tan avanzadas como las ofrecidas por RDWs.
-
Cifrado a nivel de columna (Column-Level Encryption): Los RDWs pueden proporcionar encriptación a nivel de columna, lo que permite encriptar datos sensibles en columnas específicas, mientras que Delta Lake no tiene un soporte nativo para esta funcionalidad.
-
Estas diferencias destacan que, aunque Delta Lake ofrece muchas ventajas en términos de flexibilidad y capacidad de manejo de datos, los RDWs aún mantienen ciertas ventajas en términos de rendimiento de consulta y características de seguridad avanzadas.
9. Recursos complementarios
Enlaces a recursos adicionales para profundizar en los temas tratados en este documento:
-
Tecnologías
-
Tutoriales