Resumen
En este laboratorio se trabaja el despliegue de infraestructura con Terraform en clouds diferentes. Se practicará creando infraestuctura en Google Storage. Posteriormente, se preparará una máquina virtual con MySQL en OpenStack y dos máquinas virtuales más con Docker también en OpenStack para el despliegue de una API y una aplicación, respectivamente.
-
Trabajar con varios providers Terraform
-
Automatizar la creación e inicialización de infraestructura cloud
-
Organizar el código Terraform en módulos
1. Recursos
Puedes aprender a usar Terraform siguiendo el Tutorial Despliegue de infraestructura cloud con Terraform.
2. Actividades
Se trata de realizar el siguiente despligue automatizado con Terraform:
-
En Google Storage:
-
Crear un bucket inicializado con dos imágenes. Las imágenes serán públicas y se podrá acceder a ellas simplemente con su URL.
-
-
En OpenStack:
-
Crear una máquina virtual inicializada con MySQL
-
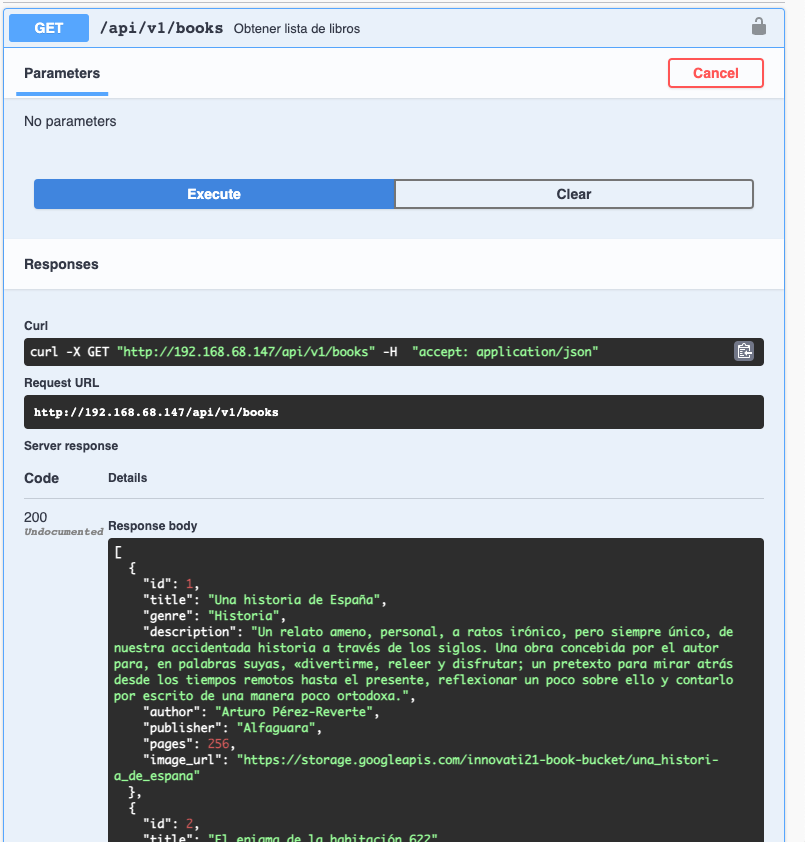
Crear una máquina virtual inicializada con Docker. En la inicialización también se desplegará un contenedor que ofrece una API sobre un catálogo de libros. Ofrece operaciones CRUD y ofrece la documentación en Swagger en
url/docspara poder interactuar con la API. La API interactúa con la base de datos MySQL anterior. -
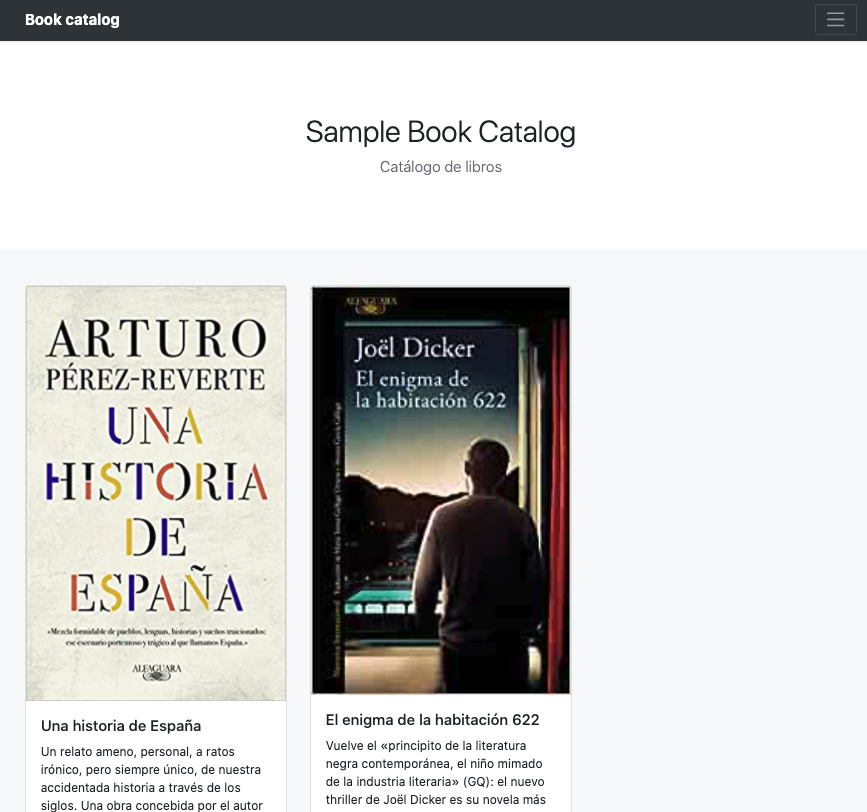
Crear una máquina virtual inicializada con Docker. En la inicialización también se desplegará un contenedor que ofrece una aplicación que muestra un catálogo de libros. Recupera los datos de los libros de la API anterior y la imagen de la portada del bucket creado en Google Storage.
-
La aplicación tiene este aspecto.
|
Se deber tener a mano la clave JSON de Cuenta de servicio del proyecto Google Cloud (más información). |
Tomar como base el código de la carpeta Mixto del repositorio de ejemplos Terraform de este laboratorio siguiendo estos pasos para configurar el ejercicio. Contiene:
-
Organización de la configuración en dos módulos (
Google-StorageyOpenStack). Los módulos están dentro de una carpetamodulespara una mejor organización. Cada módulo configura infraestructura en el proveedor cloud correspondiente. Cada módulo contiene:-
Un archivo
providers.tf(configuración del proveedor cloud). -
Un archivo
variables.tf(configuración de variables) -
Un archivo
main.tf(configuración de los recursos del despliegue). -
El módulo
OpenStackademás tiene el archivoversions.tfpara adaptar a la versión 0.13 de Terraform.
-
-
Archivo
main.tfcon la llamada a los dos módulos anteriores. -
Archivo
gcp-identity.jsoncuyo contenido debe ser reemplazado por la clave JSON de una Cuenta de servicio del proyecto Google Cloud. Mantener el nombre del archivogcp-identity.json. -
Archivo
install_mysql.shque instala un servidor MySQL en Ubuntu. El script inicializa una base de datos denominadaSGde artículos deportivos, configura el acceso desde cualquier dirección IP y configura la clave derootamy_password. -
Archivo de plantilla
setup-api-docker.tplque instala Docker y lanza un contenedor con la API de la aplicación. En la plantilla hay que configurar la ejecución de un contenedor que propociona una API sobre los productos del catálogo de la base de datos. -
Archivo de plantilla
setup-app-docker.tplque instala Docker y lanza un contenedor con la aplicación. En la plantilla hay que configurar la ejecución de un contenedor que propociona la aplicación del catálogo de productos interactuando con la API.
2.1. Creación e inicialización del bucket en Google Storage
-
Cambiar el contenido del archivo
gcp-identity.jsoncon el contenido del archivo JSON de clave de la cuenta de servicio del proyecto en Google Cloud. -
En
modules/Google-Storagemodificar:-
provider.tfpara configurar Google Cloud como provider -
variables.tfcon las variables indicadas -
main.tfsiguiendo las instrucciones de los recursos a crear.
-
2.2. Creación e inicialización de las máquinas virtuales en OpenStack
-
En
modules/OpenStackmodificar:-
los arhivos de plantilla siguiendo las instrucciones indicadas en
YOUR CODE HERE. -
provider.tfpara configurar OpenStack como provider -
variables.tfcon las variables indicadas -
main.tfsiguiendo las instrucciones de los recursos a crear.
-
|
Se recomienda partir de un proyecto nuevo propio e ir añadiendo paulatinamente fragmentos del código del repositorio de base e ir construyéndolo poco a poco:
|
Inicialmente la base de datos está vacía. El contenedor de la API contiene la documentación en Swagger y permite la interacción directa con la base de datos. Para cargar datos, abrir el método POST. Inicialmente muestra esta información sobre la creación de un nuevo libro.
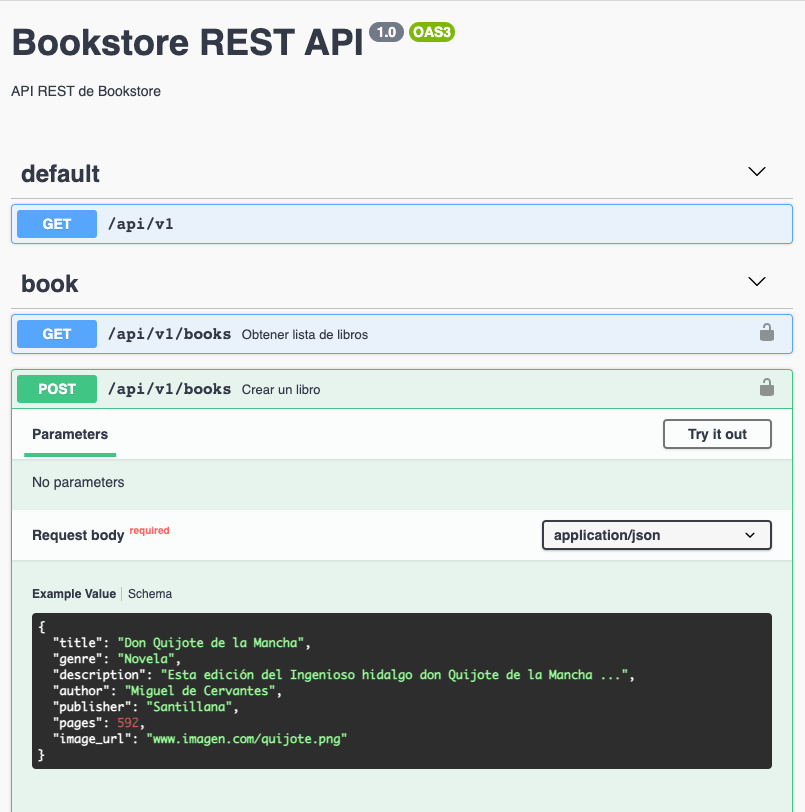
Pulsar el botón Try out en la operación POST, sustituir los valores del Quijote de la Mancha de ejemplo por este valor JSON modificando el valor del <bucket-full-name> en image_url por su valor adecuado (p.e. cc2021-mtorres-book-bucket)
{
"title": "Una historia de España",
"genre": "Historia",
"description": "Un relato ameno, personal, a ratos irónico, pero siempre único, de nuestra accidentada historia a través de los siglos. Una obra concebida por el autor para, en palabras suyas, «divertirme, releer y disfrutar; un pretexto para mirar atrás desde los tiempos remotos hasta el presente, reflexionar un poco sobre ello y contarlo por escrito de una manera poco ortodoxa.",
"author": "Arturo Pérez-Reverte",
"publisher": "Alfaguara",
"pages": 256,
"image_url": "https://storage.googleapis.com/<bucket-full-name>/una_historia_de_espana"
}Al pulsar Execute se enviará la petición a la base de datos y se creará el libro.
Repetir la operación para el libro
{
"title": "El enigma de la habitación 622",
"genre": "Ficción contemporánea",
"description": "Vuelve el «principito de la literatura negra contemporánea, el niño mimado de la industria literaria» (GQ): el nuevo thriller de Joël Dicker es su novela más personal. ",
"author": "Joël Dicker",
"publisher": "Alfaguara",
"pages": 624,
"image_url": "https://storage.googleapis.com/<bucket-full-name>/el_enigma_de_la_habitacion_622"
}Los libros almacenados se pueden recuperar con el endpoint GET api/v1/books pulsando sobre Try out y a continuación Execute. Devolverá algo así: