
Resumen
|
TRABAJO EN CURSO |
-
Conocer la importancia del uso de Kubernetes en el ciclo de vida de las aplicaciones actuales.
-
Introducir los conceptos básicos de Kubernetes.
-
Desplegar aplicaciones con archivos YAML.
-
Aprender a usar objetos básicos de Kubernetes, como Pod, Deployment, Service, ConfigMap, Secret y HPA.
-
Usar Minikube para el desarrollo y prueba en local.
-
Usar
kubectlpara la administración básica de Kubernetes. -
Escalar aplicaciones de forma automática en función del uso de la CPU.
-
Realizar actualizaciones en caliente (rolling updates).
-
Aprender a manejar volúmenes en el cluster y externos.
-
Aprender a usar Init Containers para la inicialización de contenedores en su creación.
-
Aprender a usar Kubernetes Dashboard.
|
Disponibles los repositorios usados en este seminario: |
1. Introducción
La adopción de Docker sigue creciendo de forma imparable y cada vez más organizaciones lo usan en producción. Por tanto, se hace necesario contar con una plataforma de orquestación que permita administrar y escalar los contenedores.
Supongamos que hemos comenzado a usar Docker y hemos hecho un despliegue de un par de servidores. De pronto, la aplicación comienza a tener un gran tráfico de entrada y hay que escalar a una gran cantidad de servidores para atender la demanda. Aquí es donde entra Kubernetes para hacer tareas del tipo dónde debe ir un contenedor, cómo se monitorizan esos contenedores, cómo se reinician cuando tengan un problema, quiero escalar de forma automática de 1 a 20 réplicas en función de la carga. Incluso, con componentes como Istio, podemos derivar porcentajes de tráfico a distintas versiones desplegadas de una aplicación o servicio, derivar tráfico a las versiones en función de la red o IP desde la que se reciben las peticiones o en función del usuario que realiza la petición.
Por funcionalidades como estas y otras más sorprendentes aún son por la que posiblemente te planteará que debes poner en tu vida un orquestador como Kubernetes ;-)
2. Conceptos básicos
Kubernetes es una plataforma de código abierto para despliegue, escalado y gestión de aplicaciones contenedorizadas.
Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Kubernetes services, support, and tools are widely available.
The name Kubernetes originates from Greek, meaning helmsman or pilot. Google open-sourced the Kubernetes project in 2014. Kubernetes builds upon a decade and a half of experience that Google has with running production workloads at scale, combined with best-of-breed ideas and practices from the community.
Kubernetes ofrece una abstracción en la que permite el despliegue de aplicaciones en un cluster sin pensar en las máquinas que lo soportan.
2.1. Cluster de Kubernetes
Un cluster de Kubernetes está formado por dos tipos de recursos (referidos a máquinas, ya sean físicas o virtuales):
-
El Master coordina el cluster. Coordina todas las actividades del cluster como organizar (schedule) las aplicaciones, mantener el estado deseado de las aplicaciones, escalado, despliegue de actualizaciones, y demás. También recoge información de los nodos worker y Pods (unidades mínimas de despliegue en Kubernetes. Contienen al menos un contenedor) .
-
Los Nodos son workers que ejecutan las aplicaciones. Cada nodo contiene un agente denominado Kubelet que gestiona el nodo y mantiene la comunicación con el Máster. El nodo también tiene herramientas para trabajar con contenedores, como por ejemplo Docker.
|
Un cluster Kubernetes en producción debería tener al menos 3 nodos. En entornos de producción se usan varios nodos máster para que los clusters sean tolerantes a fallos y ofrezcan alta disponibilidad. |

Al desplegar una aplicación en Kubernetes el Master inicia los contenedores de la aplicación. El máster organiza los contenedores para que se ejecuten en los nodos (worker) del cluster. Los nodos se comunican con el master usando la API de Kubernetes. La API es expuesta a través del nodo Master y es posible usarla directamente para intectuar con el cluster.
|
Una aplicación de tratamiento de imágenes y que esté basada en contenedores podría interactuar con la API de Kubernetes solicitando a demanda la creación de pods dedicados a operaciones específicas (p.e. filtrado, aclarado, …) en respuesta a las acciones de los usuarios. Una vez finalizada la operación, la aplicación volvería a interactuar con la API de Kubernetes para la liberación de los pods creados para la resolución de la tarea. |
$ curl http://<kubernetes_home>/api/v1/namespaces/default/pods{
"kind": "PodList",
"apiVersion": "v1",
"metadata": {
"selfLink": "/api/v1/namespaces/default/pods",
"resourceVersion": "10803"
},
"items": [
{
"metadata": {
"name": "hello-minikube-64c7df9db-ffwtn",
"generateName": "hello-minikube-64c7df9db-",
"namespace": "default",
"selfLink": "/api/v1/namespaces/default/pods/hello-minikube-64c7df9db-ffwtn",
"uid": "652c298a-6dc2-4aec-a72f-390669fed6d2",
"resourceVersion": "10608",
"creationTimestamp": "2019-07-08T18:02:23Z",
"labels": {
"pod-template-hash": "64c7df9db",
"run": "hello-minikube"
},
....Los clusters de Kubernetes se pueden desplegar sobre máquinas físicas o virtuales. Para comenzar a practicar con Kubernetes o para tareas de desarrollo, Minikube es una buena opción. En la sección Minikube se presenta más información sobre esta plataforma. Minikube está disponible para Windows, Linux y MacOS.
2.2. Arquitectura de Kubernetes
Tal y como hemos introducido en el apartado anterior, un cluster de Kubernetes está formado por dos tipos de unidades, el nodo Master y los nodos Worker (o siemplemente Nodos).
La figura siguiente ilustra estas dos unidades, así como algunos de los componentes más importantes en su interior.
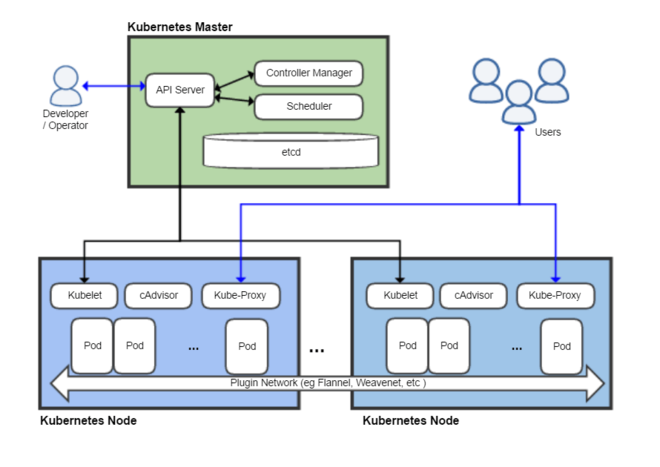
-
Plugins de red: Permiten la conexión entre pods de nodos diferentes y la integración de soluciones de red diferentes (overlay, L3, …)
-
etcd: una base de datos clave-valor donde Kubernetes guarda todos los datos del cluster. -
API server: Componente del Master que expone la API de Kubernetes. Es el front-end del plano de control de Kubernetes.
-
Control Manager: Se encarga de comprobar si el estado deseado coincide con la realidad (p.e. número de réplicas)
-
Scheduler: Componente del master que observa qué pods se han creado nuevos y no tienen nodo asignado, y les selecciona un nodo donde se puedan ejecutar.
-
kubelet: Agente que se se ejecuta en cada nodo worker del cluster y que asegura que los nodos están en ejecución y sanos.kubeletno gestiona los pods que no han sido creados por Kubernetes. -
kube-proxy: Mantiene las reglas de networking en los nodos para los pods que se ejecutan en él de acuerdo con las especificaciones de los manifiestos. -
cAdvisor: Recoge datos de uso de los contenedores. -
Plano de control o Control plane: Nivel de orquestación de contenedores que expone la API para definir, desplegar y gestionar el ciclo de vida de los contenedores.
-
Plano de datos o Data Plane: Nivel que proporciona los recursos, como CPU, memoria, red y almacenamiento, para que los pods se puedan ejecutar y conectar a la red.
|
etcd, es una base de datos clave-valor fiable y distribuida para los datos más críticos de un un sistema distribuido. Dado que Kubernetes guarda todos los datos del cluster en ella, se deberían mantener copias de seguridad de esta base de datos y disponer de un plan de recuperación ante posibles desastres. |
|
Los componentes Un ejercicio interesante es detener el contenedor |
2.3. Objetos de Kubernetes
Kubernetes ofrece una serie de objetos básicos y una serie de abstracciones de nivel superior llamadas Controladores.
Los objetos básicos de Kubernetes son:
-
Pod
-
Service
-
Volume
-
Namespace
Los objetos de nivel superior o Controladores se basan en los objetos básicos y ofrecen funcionalidades adicionales sobre los objetos básicos:
-
ReplicaSet
-
Deployment
-
StatefulSet
-
DaemonSet
-
Job
3. Minikube
-
Minikube es una implementación ligera de Kubernetes que crea una máquina virtual localmente y despliega un cluster sencillo formado por un solo nodo.
-
Minikube es una gran herramienta para el desarrollo de aplicaciones Kubernetes y permite características habituales como LoadBalancer, NodePort, volúmenes persistentes, Ingress, dashboard, reglas de acceso, y demás.
En la página de GitHub de Minikube se encuentra información sobre el proyecto, instalación y otros temas de interés.
Una vez instalado, probaremos los comandos básicos:
-
Iniciar un cluster:
minikube start
|
La primera vez que ejecutemos este comando descargará la ISO de Minikube, que son unos 130 MB, y creará la máquina virtual correspondiente. Después, la preparará para Kubernetes y tras unos minutos estará disponible minikube en nuestro puesto de trabajo. |
-
Acceso al Dashboard de Kubernetes:
minikube dashboard -
Una vez iniciado, se podrá interactuar con el cluster usando
kubectl(que veremos en la sección kubectl (el CLI de Kubernetes)) como con cualquier cluster Kubernetes:-
Iniciar un servidor de ejemplo en Minikube:
kubectl run hello-minikube --image=k8s.gcr.io/echoserver:1.4 --port=8080 -
Exponer un servicio como un NodePort:
kubectl expose deployment hello-minikube --type=NodePort -
Abrir el endpoint del servicio en el navegador:
minikube service hello-minikubeEl servidor de ejemplo iniciado muestra información sobre el cliente en el que se está ejecutando y sobre las cabeceras. Dicho servidor es expuesto en el cluster de Kubernetes como un NodePort. El resultado tras mostrarlo con
minikube service hello-minikubeserá algo similar al de la figura siguiente.Un NodePort es una forma de exponer un servicio mediante la IP del nodo en el que está el pod y un puerto estático (NodePort). De forma predeterminada el rango de puertos para NodePort es 30000-32767.
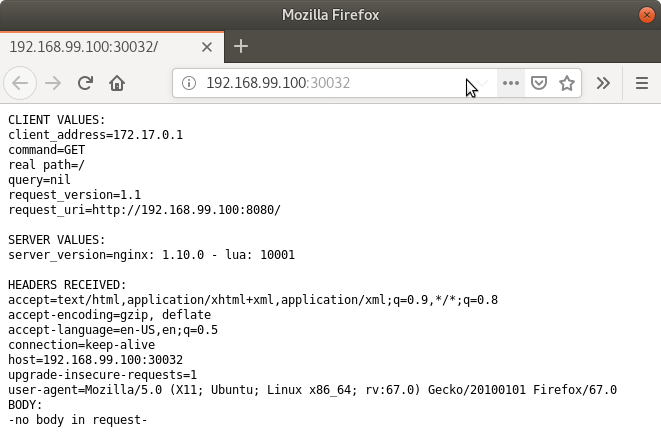
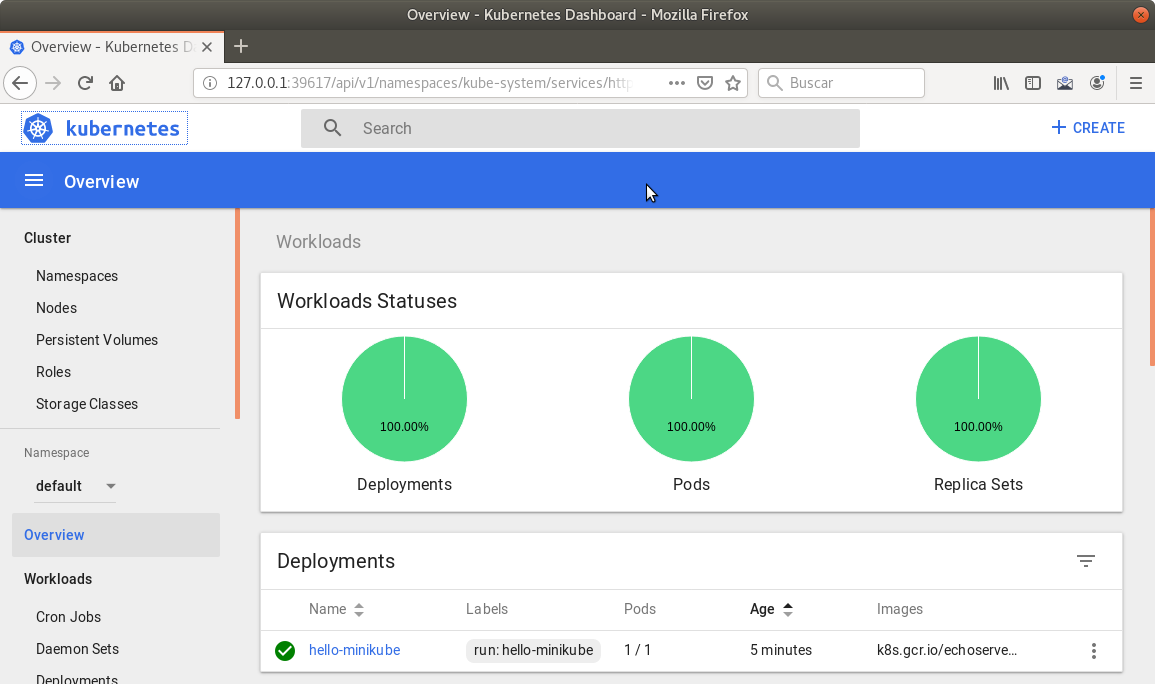
Si ahora abrimos el dashboard con
minikube dashboard, se mostraría algo similar a lo de la figura siguiente. En la figura se observa cómo ha sido creado el Deploymenthello-minikube.Un Deployment es un objeto Kubernetes que de forma declarativa especifica, entre otros, la imagen usada para desplegar los pods, el número de réplicas deseadas, recursos (RAM, CPU, …) solicitados para los pods, y demás.
-
Si ahora probamos a eliminar el pod creado, veremos que se vuelve a crear. Esto se debe a que el objeto Deployment hello-minikube creado anteriormente (con la orden kubectl run hello-minikube --image=k8s.gcr.io/echoserver:1.4 --port=8080) se encarga de mantener el número de réplicas especificado (1 de forma predeterminada). Realmente, si queremos eliminar el pod de forma permanente tendríamos que eliminar el objeto Deployment. Un poco más adelante veremos cómo hacerlo.
4. kubectl (el CLI de Kubernetes)
Para la interacción con un cluster local o remoto de Kubernetes mediante comandos se usa kubectl, un CLI sencillo que nos permitirá realizar tareas habituales como despliegues, escalar el cluster u obtener información sobre los servicios en ejecución. kubectl es el CLI para interactuar con el servidor de la API de Kubernetes.
|
Para más información, consultar la página oficial de instalación y configuración de |
Para interactuar con unos ejemplos sencillo con kubectl podemos
-
Obtener información de la versión
$ kubectl version Client Version: version.Info{Major:"1", Minor:"16", GitVersion:"v1.16.3", GitCommit:"b3cbbae08ec52a7fc73d334838e18d17e8512749", GitTreeState:"clean", BuildDate:"2019-11-14T04:24:34Z", GoVersion:"go1.12.13", Compiler:"gc", Platform:"darwin/amd64"} Server Version: version.Info{Major:"1", Minor:"16", GitVersion:"v1.16.2", GitCommit:"c97fe5036ef3df2967d086711e6c0c405941e14b", GitTreeState:"clean", BuildDate:"2019-10-15T19:09:08Z", GoVersion:"go1.12.10", Compiler:"gc", Platform:"linux/amd64"} -
Obtener información del cluster
$ kubectl cluster-info Kubernetes master is running at https://192.168.99.100:8443 KubeDNS is running at https://192.168.99.100:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy -
Obtener los nodos que forman el cluster
$ kubectl get nodes NAME STATUS ROLES AGE VERSION minikube Ready master 3d23h v1.15.0 -
Otras operaciones de interés son:
-
kubectl get podspara listar todos los pods desplegados. -
kubectl get allpara listar todos los objetos desplegados. -
kubectl describe <resource>para obtener información detallada sobre un recurso. -
kubectl logs <pod>para mostrar los logs de un contenedor en un pod. -
kubectl exec <pod> <command>para ejecutar un comando en un contenedor de un pod.
-
5. Componentes de Kubernetes en acción
5.1. Deployments
Una configuración de Deployment pide a Kubernetes que cree y actualice las instancias de una aplicación. Tras crear el Deployment, el Master organiza las instancias de aplicación en los nodos disponibles del cluster.

Una vez creadas las instancias de aplicación, el Controlador de Deployment de Kubernetes monitoriza continuamente las instancias. Si un nodo en el que está una instancia cae o es eliminado, el Controlador de Deployment de Kubernetes sustituye la instancia por otra instancia en otro nodo disponible del cluster.
Esta funcionalidad de autocuración de las aplicaciones supone un cambio radical en la gestión de las aplicaciones. Esta característica de recuperación de fallos mediante la creación de nuevas instancias que reemplazan a las defectuosas o desaparecidas no existía antes de los orquestadores.
Al crear un Deployment se especifica la imagen del contenedor que usará la aplicación y el número de réplicas que se quieren mantener en ejecución. El número de réplicas se puede modificar en cualquier momento actualizando el Deployment.
5.1.1. Despliegue de una aplicación
Podemos ejecutar una aplicación con kubectl run indicando el nombre que se dará al Deployment y el nombre de la imagen (Docker) usada para la aplicación.
$ kubectl run jsonproducer --image=ualmtorres/jsonproducer:v0 --port 80 (1)
deployment.apps/jsonproducer created| 1 | El puerto hace referencia al puerto que usa la aplicación original, es decir su contenedor, para servir su contenido. |
Este comando ha hecho que el Master haya buscado un nodo para ejecutar la aplicación, haya programado la ejecución de la aplicación en ese nodo y haya configurado el cluster para programar la ejecución de otra instancia cuando sea necesario.
|
Para imágenes que no estén en Docker Hub se pasa la URL completa del repositorio de imágenes. |
Para obtener los Deployments disponibles
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
jsonproducer 1/1 1 1 8sPara poder acceder a la aplicación deberemos primero exponerla en el cluster de Kubernetes. Más adelante veremos los detalles. Por ahora, basta con ejecutar el comando siguiente, el cual creará un servicio asociado a nuestro Deployment para poder acceder a la aplicación.
$ kubectl expose deployment jsonproducer --type=NodePort
service/jsonproducer exposedPara ver la ejecución de la aplicación, pediremos a Minikube que nos muestre el servicio con el comando
$ minikube service jsonproducerEsto abrirá un navegador y el resultado del servicio es un JSON similar a este:
{"nombre":"manolo"}5.2. Pods
Al crear el Deployment anterior, Kubernetes creó un Pod para ejecutar una instancia de la aplicación. Un Pod es una abstracción de Kubernetes que representa un grupo de uno o más contenedores de una aplicación y algunos recursos compartidos de esos contenedores (p.e. volúmenes, redes)
|
Un ejemplo de pod con más de un contenedor lo encontramos en lo que se denominan sidecars. Ejemplos de sidecar los encontramos en aplicaciones que registran su actividad en un contenedor (sidecar) dentro del mismo pod y publican la actividad en una aplicación que monitoriza el cluster. Otro ejemplo de sidecar es el de un contenedor sidecar que proporciona un certificado SSL para comunicación https al contenedor de la aplicación. Otro ejemplo más lo podemos encontrar en un sidecar que actúa como volumen. |
Los contenedores de un pod comparten una IP y un espacio de puertos, y siempre van juntos y se despliegan juntos en un nodo. La figura siguiente ilustra varias configuraciones de pods:
-
Pod 1: Un pod con un contenedor
-
Pod 2: Un pod con un contenedor y un volumen
-
Pod 3: Un pod con dos contenedores que comparten un volumen
-
Pod 4: Un pod con varios contenedores y varios volúmenes

Los pods son la unidad atómica de Kubernetes. Al crear un despliegue en Kubernetes, el Deployment crea Pods con contenedores en su interior. Cada pod queda ligado a un nodo y sigue allí hasta que se finalice o se elimine. En caso de fallo del nodo se planifica la creación de sus pods en otros nodos disponibles del cluster.
|
Los pods son efímeros, por lo que su almacenamiento desaparece al eliminar el pod. Por este motivo es necesario saber utilizar almacenamiento externo para que los datos persistan. La sección [Almacenamiento externo] estudia esta funcionalidad. |
5.2.1. Creación de un pod para MongoDB mediante un archivo de manifiesto
Los pods, al igual que otros recursos de Kubernetes (ReplicaSets, volúmenes, …) se pueden crear sobre la marcha con el CLI indicando la imagen a partir de la que se crean, o se pueden crear a partir de archivos de manifiesto. Estos archivos de manifiesto se escriben en sintaxis YAML y representan una forma declarativa de definir los recursos del cluster Kubernetes. En la sección Despliegue de aplicaciones mediante archivos YAML se trata este tema.
Para ilustrar cómo crear un pod mediante una manifiesto YAML, veremos cómo crear uno sencillo para MongoDB. Para ir familiarizándonos con Kubernetes, probaremos también con unos comandos básicos para mostrar información, mostrar los logs y redirección de puertos
-
Creación del manifiesto YAML
Archivo
mongodb-basico.yamlapiVersion: v1 kind: Pod metadata: name: mongodb spec: containers: - image: mongo name: mongodb -
Despliegue del manifiesto para crear el pod
$ kubectl apply -f mongodb-basico.yaml -
Inicio de sesión SSH en el pod
$ kubectl exec -it mongodb /bin/bash -
Mostrar información del pod
$ kubectl describe pod mongodb -
Mostrar los logs del pod
$ kubectl logs mongodb -
Redirección del puerto del pod a un puerto local (establece un túnel SSH entre nuestro equipo y el pod con los puertos indicados)
$ kubectl port-forward mongodb 27017:27017Para poder probar el comando anterior de la redirección de puertos necesitaremos disponer de un cliente MongoDB instalado en nuestro equipo.
-
Eliminación del pod
$ kubectl delete -f mongodb-basico.yaml
Los pods se ejecutan en un Nodo. Un nodo es una máquina worker (física o virtual) del cluster. Los nodos están gestionados por el Master. Un Nodo puede contener muchos pods.

Cada Nodo ejecuta al menos:
-
Kubelet, un proceso que se encarga de la comunicación entre el nodo y el Master. Gestiona los pods y los contenedores que se están ejecutando en el nodo. -
Un motor de contenedores, como Docker, que se encarga de la descarga de imágenes de un registro y de ejecutar la aplicación.
5.3. Servicios
Se dice que en Kubernetes los pods son mortales o efímeros. Cuando un nodo desaparece (bien por un error o por una desconexión), los contenedores que están en el nodo también se pierden. En ese momento, un ReplicaSet se encarga de devolver el cluster al estado deseado y organiza la creación de nuevos pods en otros nodos disponibles para mantener funcionando la aplicación. Las réplicas de los pods han de ser intercambiables y aunque cada pod en el cluster tenga su propia IP única, Kubernetes reconcialiará los cambios entre los pods para que las aplicaciones sigan funcionando.
Los servicios en Kubernetes son una abstracción que definen un conjunto lógico de pods y una política de acceso a ellos estableciendo un nombre para acceder a ellos. Esto permite que haya un acoplamiento débil entre pods dependientes. El acceso puede ser interno o externo al cluster. De esta forma, las aplicaciones sólo usarán los nombres de los servicios y no las IP de los pods, ya que éstas nunca son fijas debido a que, por un lado, los pods se crean y se destruyen para mantener el número de réplicas deseado; y por otro lado, un pod puede ser sustituido por otro ante un problema y el nuevo pod tendrá una IP diferente.
Los pods pueden ser etiquetados con metadatos. Estos metadatos posteriormente pueden ser usados por otros objetos Kubernetes (p.e. ReplicaSet, Deployment) para seleccionar los pods y crear una unidad lógica (p.e. todas las réplicas de un contenedor de frontend)
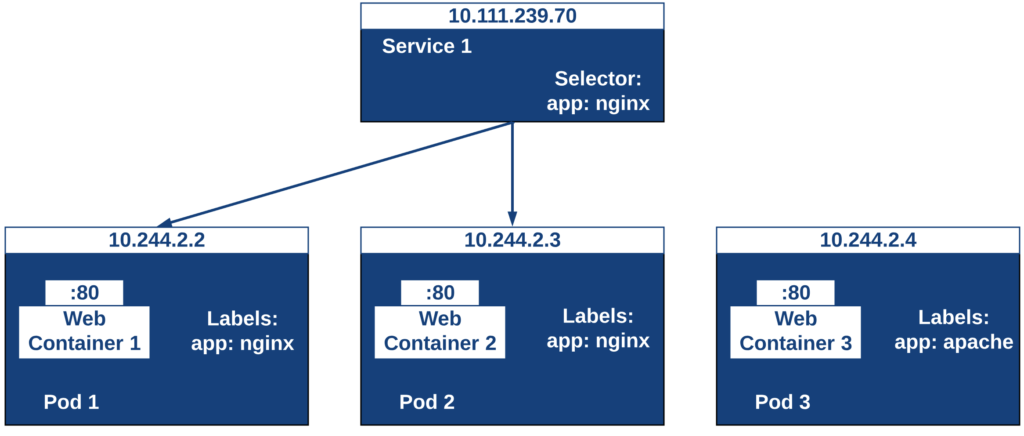
La figura siguiente ilustra como un servicio agrupa mediante el selector app:ngnix a aquellos pods que están etiquetados con app:ngnix.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels: (1)
app: nginx
template:
metadata:
labels: (2)
app: nginx
spec:
containers:
- name: webcontainer
image: nginx
ports:
- containerPort: 80| 1 | Condición para buscar |
| 2 | Condición para ser encontrado |
Al desplegar este deployment se crearán dos pods (replicas: 2), que quedarán agrupados por la coincidencia entre el selector que pide el deployment (app: nginx) y la etiqueta con los que son creados los pods (app: nginx).
$ kubectl apply -f ngnix.yamlSi ahora vemos los detalles del deployment en el dashboard de Minikube veremos que los dos pods de Nginx creados están agrupados lógicamente en el deployment ngnix. Esta información está realmente en el objeto ReplicaSet creado por el Deployment.
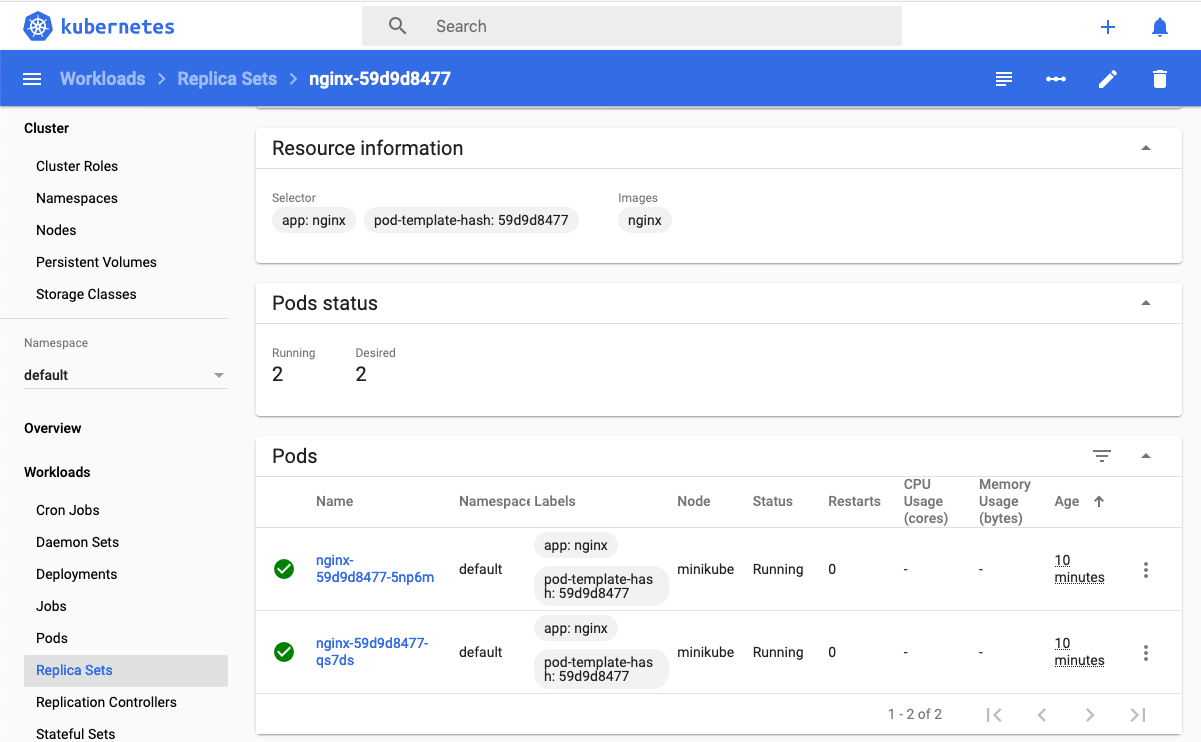
Cada pod tiene una dirección IP única, pero esa IP no se expone fuera del cluster sin lo que se denomina un Servicio. Los servicios pemiten que las aplicaciones reciban tráfico.
5.3.1. Tipos de servicio
En función del ámbito de la exposición del servicio tenemos:
-
ClusterIP: El servicio recibe una IP interna a nivel de cluster y hace que el servicio sólo sea accesible a nivel de cluster. -
NodePort: Expone el servicio fuera del cluster concatenando la IP del nodo en el que está el pod y un número de puerto entre 30000 y 32767, que es el mismo en todos los nodos -
LoadBalancer: Crea en cloud, si es posible, un balanceador externo con una IP externa asignada. -
ExternalName: Expone el servicio usando un nombre arbitrario (especificado enexternalName)

Los servicios enrutan el tráfico entre los pods proporcionando una abstracción que permite que los pod mueran y se repliquen sin impactar en la aplicación.
|
El descubrimiento y enrutado entre pods dependientes (p.e. frontend y backend) son gestionados por los Servicios. Los servicios agrupan a sus pods usando etiquetas y selectores. Los servicios usan selectores y los pods son creados con etiquetas. Su emparejamiento por valores coincidentes es lo que agupa los pods en un servicio. |
Las etiquetas son pares clave-valor y tienen usos muy variados:
-
Seleccionar los objetos de un despliegue
-
Diferenciar entre objetos de desarrollo, prueba y producción
-
Distinguir entre versiones

En la figura se observa cómo el selector de etiquetas usado en los Deployment sirve para agrupar los pods que conforman un servicio, ya que cada pod contiene la misma etiqueta usada en el selector del Deployment al que pertenece.
Las etiquetas se pueden configurar durante la creación o en cualquier momento posterior.
|
Prueba a editar en el dashboard de kubernetes uno de los pods de Nginx cambiándole la etiqueta (p.e. |
5.3.2. Ejemplo. Creación de un servicio
Anteriormente, en la sección Despliegue de una aplicación creamos una aplicación de ejemplo que generaba un JSON de prueba. A modo de recordatorio, hicimos lo siguiente:
-
Crear un Deployment a partir de la imagen
ualmtorres/jsonproducer:v0de Docker Hub con el comando$ kubectl run jsonproducer --image=ualmtorres/jsonproducer:v0 --port 80Podemos consultar el Deployment existente con el comando siguiente. Si por cualquier motivo no se dispone del Deployment, basta con ejecutar el comando anterior para crearlo.
$ kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE jsonproducer 1/1 1 1 17mEste Deployment habrá creado un pod que estará ejecutando la aplicación disponible de la imagen utilizada. Podemos ver los pods disponibles con el comando
$ kubectl get pods NAME READY STATUS RESTARTS AGE jsonproducer-7769d76894-2nzt2 1/1 Running 0 23m -
Crear un servicio para poder exponer la aplicación al exterior. Concretamente usamos un servicio de tipo NodePort, lo que nos sirve la aplicación concatenando la IP del nodo donde está el pod y un puerto aleatorio. El servicio lo creamos con
$ kubectl expose deployment jsonproducer --type=NodePortPodemos consultar el servicio existente con el comando siguiente. Si por cualquier motivo no se dispone del servicio, basta con ejecutar el comando anterior para crearlo.
$ kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE jsonproducer NodePort 10.99.116.165 <none> 80:30737/TCP 25m (1) kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 34d (2)1 Este es nuestro servicio. En el caso del tutorial, el puerto aleatorio asignado es el 30737 2 Servicio kubernetescreado de forma predetermianda al iniciarse MinikubePodemos acceder el servicio creado con
$ minikube service jsonproducer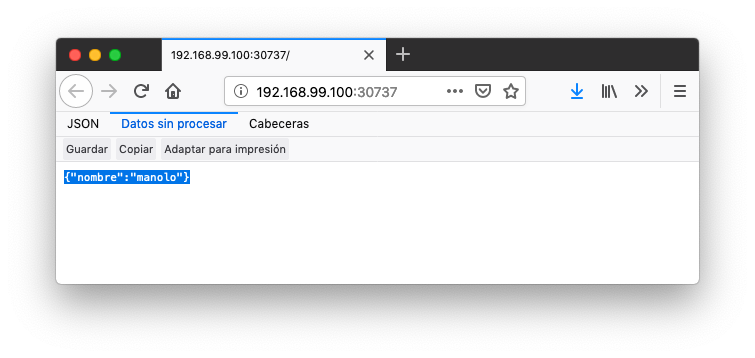
Si queremos consultar la información del servicio creado usaremos la opción
describedekubectl$ kubectl describe services jsonproducer (1) Name: jsonproducer Namespace: default Labels: run=jsonproducer (2) Annotations: <none> Selector: run=jsonproducer Type: NodePort IP: 10.99.116.165 Port: <unset> 80/TCP TargetPort: 80/TCP NodePort: <unset> 30737/TCP Endpoints: 172.17.0.5:80 Session Affinity: None External Traffic Policy: Cluster Events: <none>1 Pasamos el nombre de nuestro servicio como parámetro 2 Etiqueta añadida de forma predeterminada Si ahora consultamos la información del pod de la aplicación veremos que coincide la etiqueta. Recordemos que al introducir el concepto de Servicio se indicó que era una abstracción para agrupar pods y que utilizaba etiquetas para poder reunirlos. He aquí la correspondencia entre la etiqueta del servicio y la etiqueta de los pods del servicio.
$ kubectl get pods (1)
NAME READY STATUS RESTARTS AGE
jsonproducer-7769d76894-2nzt2 1/1 Running 0 49m
$ kubectl describe pods jsonproducer-7769d76894-2nzt2 (2)
Name: jsonproducer-7769d76894-2nzt2
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: minikube/10.0.2.15
Start Time: Mon, 15 Jul 2019 18:56:20 +0200
Labels: pod-template-hash=7769d76894
run=jsonproducer (3)
Annotations: <none>
Status: Running
IP: 172.17.0.5
Controlled By: ReplicaSet/jsonproducer-7769d76894 (4)
Containers:
jsonproducer:
Container ID: docker://52e290262984a94da4dd89102b93d80f59c0c4310c303dac67b02884d73fb545
Image: ualmtorres/jsonproducer:v0 (5)
...| 1 | Obtener primero los pods disponibles para poder acceder al pod deseado |
| 2 | Obtener información del pod |
| 3 | Etiqueta coincidente con el selector (etiqueta) del Deployment |
| 4 | ReplicaSet encargado de mantener el número de pods deseados para el Deployment |
| 5 | Imagen base usada para crear el único contenedor de este pod |
5.4. Volúmenes
Básicamente, un volumen es un directorio para datos que es accesible a los contenedores de un Pod y que persiste a los reinicios de un Pod. El medio que se use para el almacenamiento y cómo se comporte ante una eliminación del Pod depende del tipo de volumen que se use.
Para usar un volumen, un Pod especifica el volumen que proporciona al Pod (el campo .spec.volumes) y donde montarlo en los contenedores (el campo .spec.containers.volumeMounts). Dejamos por ahora el tema de los volúmenes para volver a ellos más adelante cuando usemos archivos de despliegue.
5.5. ConfigMaps
Los objetos ConfigMap permiten almacenar datos en forma de pares clave-valor para que puedan usarse posteriormente en despliegues parametrizados y hacerlos más portables.
Usaremos los ConfigMap para almacenar datos no sensibles sobre la configuración. Deben ser datos no sensibles porque los datos se guardan tal cual.
-
Creación de un ConfigMap con valores directamente:
$ kubectl create configmap datosmtorres --from-literal=nombre=Manuel --from-literal=apellidos=Torres -
Creación de un ConfigMap desde archivos:
$ kubectl create configmap datosstevemcqueen --from-file=nombre=nombre.txt --from-file=apellidos=apellidos.txt
|
Los archivos que contienen los valores que alimentarán las claves no contendrán caracteres no deseados como espacios o saltos de línea al final. |
-
Obtener los datos de un ConfigMap
$ kubectl describe configmap datosmtorres $ kubectl describe configmap datosstevemcqueen -
Eliminar un ConfigMap
$ kubectl delete configmap datosmtorres $ kubectl delete configmap datosstevemcqueen
5.6. Secrets
Los objetos Secret se usan para almacenar información sensible, como contraseñas, tokens OAuth y claves ssh. Colocar esta información en objetos Secret es más seguro que colocarla en texto plano y legible.
No obstante, los datos de los objetos Secret no están cifrados. Están codificados en base64 y pueden hacerse visibles fácilmente. Sistemas como Vault son usados de forma complementaria para aumentar la seguridad de la información que contienen los Secret.
-
Creación de un Secret con valores directamente:
$ kubectl create secret generic my-secret --from-literal=key1=supersecret --from-literal=key2=topsecret -
Creación de un Secret desde archivos:
$ kubectl create secret generic my-second-secret --from-file=key1=key1.txt --from-file=key2=key2.txt -
Obtener los datos de un Secret:
$ kubectl get secret my-secret -o yaml -
Decodificación de un Secret:
$ echo 'yourEncodedKey' | base64 --decode -
Eliminar un Secret:
$ kubectl delete secret my-secret
5.7. Namespaces
Hasta ahora, todos los objetos que hemos creado (pods, deployments, replicasets, services, configmaps y secrets) están en el mismo lugar, en el mismo espacio. Concretamente en el espacio default. Es lo que se conoce como namespace. Los namespaces se usan para organizar objetos en un cluster, proporcionando una forma de mantener separados los recursos en el cluster. De cara a dar nombres a los recursos, los nombres sólo tienen que ser únicos a nivel de namespace, pero no a nivel de cluster.
|
En clusters con varios usuarios los namespaces proporcionan una forma de agrupar los recursos de cada usuario. Además, los administradores pueden establecer cuotas a nivel de namespace limitando a los usuarios la cantidad de objetos que pueden crear y la cantidad de recursos del cluster que pueden consumir (p.e. CPU, memoria). |
-
Crear un Namespace
$ kubectl create namespace rrhh -
Crear un pod indicando el namespace
$ kubectl run nginxrrhh --image=nginx --port 80 --namespace rrhh -
Mostrar los pods de un namespace
$ kubectl get pods --namespace rrhh -
Cambiar de namespace
kubectl config set-context --current --namespace=rrhh -
Volver al namespace default
$ kubectl config set-context --current --namespace=default -
Eliminar un namespace
$ kubectl delete namespace rrhh
|
Eliminar un namespace elimina el namespace y todos los objetos que contenga, por lo que es una operación muy peligrosa. |
|
Si se elimina un namespace estando situado sobre él no se cambia a ningún namespace por lo que habrá que cambiar a uno de los namespace existentes en nuestro sistema |
|
|
6. Escalado de una aplicación
Hasta ahora hemos creado un Deployment, el cual posteriomente fue expuesto mediante un Servicio. Como en su creacin no indicamos número de réplicas, el Deployment creó sólo un Pod para ejecutar la aplicación. Si la demanda que soporta el pod aumenta quizá puede ser conveniente aumentar el número de pods de la aplicación. Esto es lo que se conoce como escalado y hace referencia al número de réplicas en un Deployment.
|
Para escalar un Deployment durante la creación se usa el parámetro |
Al escalar una aplicación se crearán nuevos pods en los nodos con recursos disponibles. El número de pods irá aumentando paulatinamete hasta llegar al número de pods deseados. La ejecución de varias instancias trae consigo la distribución del tráfico entre todos los pods del Deployment. De esta tarea se encarga un balanceador de carga que integra el propio Servicio.
|
Escalar a 0 terminará todos los pods de un Deployment. |
Una vez que entramos en la dinámica de tener varias instancias de la misma aplicación, se pueden realizar actualizaciones en caliente (rolling updates) sin suspensión del servicio. Esto lo veremos en la sección Actualización de aplicaciones.
6.1. Ejemplo de escalado de una aplicación
En primer lugar veremos cuáles eran las condiciones del despliegue de ejemplo que estamos usando.
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
jsonproducer 1/1 1 1 68m-
READYindica el ratio entre los pods que están en ejecución y los pods deseados. -
UP-TO-DATEindica el número de réplicas que están actualizadas para alcanzar el estado deseado. -
AVAILABLEindica el número de réplicas disponibles actualmente para los usuarios.
|
Si no contamos con este deployment porque vamos limpiando el entorno en cada sección, los comandos siguientes vuelven a crear el Deployment
|
El comando siguiente escala a 4 réplicas el despliegue de ejemplo (jsonproducer)
$ kubectl scale deployments jsonproducer --replicas=4
deployment.extensions/jsonproducer scaledUnos instantes después podremos comprobar que el Deployment ya ha alcanzado el estado deseado.
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
jsonproducer 4/4 4 4 73mLa aplicación sigue disponible sin ningún cambio para el usuario final. Sin embargo, ahora hay 4 réplicas cuyo tráfico es gestionado por un balanceador de carga asociado al servicio.
La información de las réplicas la podemos obtener consultando el número de pods con el comando siguiente:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jsonproducer-7769d76894-2nzt2 1/1 Running 0 74m
jsonproducer-7769d76894-9xdqw 1/1 Running 0 38s
jsonproducer-7769d76894-nhtl4 1/1 Running 0 38s
jsonproducer-7769d76894-qbvzd 1/1 Running 0 38sSi ahora por cualquier motivo dejase de estar disponible alguno de los nodos en los que se encuentra desplegados los pods de la apliación, o bien dejase de funcionar alguno de los pods, el Controlador de Deployment de Kubernetes se encargaría de organizar la creación de nuevos pods para volver a alcanzar el estado deseado, en nuestro caso 4 réplicas.
Probemos esta funcionalidad eliminando el último pod y comprobando como Kubernetes organiza inmediatamente la creación de otro pod que lo sustituya.
$ kubectl delete pods jsonproducer-7769d76894-qbvzd
pod "jsonproducer-7769d76894-qbvzd" deleted
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jsonproducer-7769d76894-2nzt2 1/1 Running 0 85m
jsonproducer-7769d76894-9xdqw 1/1 Running 0 12m
jsonproducer-7769d76894-gh7qk 1/1 Running 0 3s (1)
jsonproducer-7769d76894-nhtl4 1/1 Running 0 12m| 1 | Pod que sustituye al pod eliminado y que es creado automáticamente para mantener el número de réplicas a 4 |
Por último, si ahora queremos reducir el número de réplicas a 2 bastará con volver a indicarlo al Deployment en el parámetro replicas y este será el nuevo estado a alcanzar.
$ kubectl scale deployments jsonproducer --replicas=2
deployment.extensions/jsonproducer scaled
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jsonproducer-7769d76894-2nzt2 1/1 Running 0 92m
jsonproducer-7769d76894-9xdqw 1/1 Running 0 18m7. Actualización de aplicaciones
Para poder realizar actualizaciones sin tener que suspender el servicio mientras se realiza la actualización, Kubernetes proporciona las rolling updates, que van actualizando los pods con la nueva versión de la aplicación.
De forma predeterminada, el número de pods que pueden estar no disponibles durante una actualización es 1, aunque esta opción es configurable, ya sea mediante cantidad o porcentaje de pods no disponibles durante la actualización. Además, es posible volver a una versión anterior.
Al igual que ocurre al escalar las aplicaciones, si el Deployment está expuesto, el Service balanceará el tráfico sólo a los pods que estén disponibles durante la actualización.
A continuación se muestra cómo actualizar el Deployment de ejemplo jsonproducer con nuevo Deployment con el mismo nombre y una nueva versión de la imagen (v1).
$ kubectl set image deployments jsonproducer jsonproducer=ualmtorres/jsonproducer:v1Al realizar la actualización de la imagen del Deployment, Kubernetes tendrá que descargar la nueva imagen y organizar la creación de los pods en los nodos con recursos disponibles. Mientras se realiza la actualización podremos ver que hay nodos que se están terminando, otros que se están creando y otros que están disponibles.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jsonproducer-7769d76894-fr7cz 1/1 Running 0 25s
jsonproducer-7769d76894-hfpr7 1/1 Terminating 0 24s
jsonproducer-c76c87f-jwhxq 0/1 ContainerCreating 0 0s
jsonproducer-c76c87f-tmbkk 1/1 Running 0 1sTras unos instantes, la aplicación dejará de servir totalmente la versión anterior de la aplicación y comenzará a servir la nueva versión. La nueva versión de la aplicación devuelve Manolo Torres en lugar de manolo en el JSON.
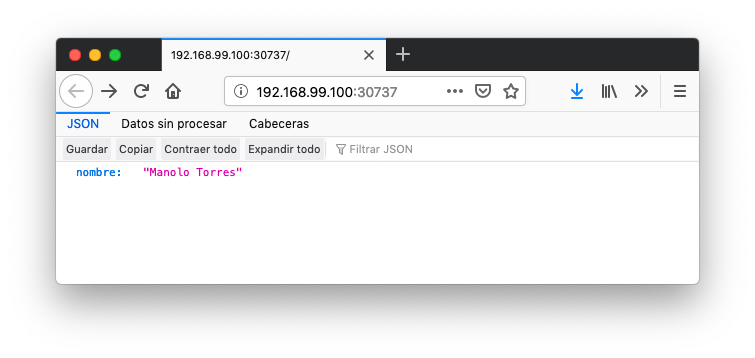
Para deshacer una actualización de una aplicación volviendo a la versión anterior haremos un rollout undo. El comando siguiente devuelve a la aplicación a la versión anterior
$ kubectl rollout undo deployments jsonproducer
deployment.extensions/jsonproducer rolled backTras este comando, el Controlador de Deployment de Kubernetes irá reemplanzando los pods hasta alcanzar el estado deseado. A continuación se ve el estado intermedio mientras se vuelve a la versión anterior.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jsonproducer-7769d76894-m22sv 1/1 Running 0 2s
jsonproducer-7769d76894-v6hfv 1/1 Running 0 4s
jsonproducer-c76c87f-jwhxq 0/1 Terminating 0 14m
jsonproducer-c76c87f-tmbkk 0/1 Terminating 0 14mTras unos instantes, se alcanzará el estado deseado
Caligari:~ manolo$ kubectl get pods
NAME READY STATUS RESTARTS AGE
jsonproducer-7769d76894-m22sv 1/1 Running 0 8s
jsonproducer-7769d76894-v6hfv 1/1 Running 0 10sY la aplicación volverá a mostrar el contenido anterior.
8. Despliegue de aplicaciones mediante archivos YAML
Hasta ahora, las interacción con Kubernetes la hemos hecho sobre la marcha, creando despliegues, servicios, escalado de aplicaciones y demás. Esto nos ha servido familiarizarnos tanto con los objetos básicos de Kubernetes (Pod, ReplicaSet, Deployment, Service, ConfigMap, Secret, Namespace, …), como con operaciones habituales (escalado, actualización de versiones, …). Sin embargo, esta no es la forma habitual. Esta forma de uso de Kubernetes está más orientada a la creación de tareas puntuales. En cambio, cuando se trata de operaciones que queremos que sean repetibles, la forma de operar consiste en crear archivos YAML especificando el objeto que se quiere crear en Kubernetes (espacio de nombres, despliegue, servicio, …). Una vez creados estos archivos, se usará kubectl para cargarlos/desplegarlos en Kubernetes.
|
El uso de archivos para despliegues Kubernetes nos permitirá además beneficiarnos de las ventajas de los sistemas de control de versiones, sometiendo nuestros recursos de Kubernetes al control de versiones, facilidad de distribución y trabajo en equipo. |
8.1. Despliegue de un Pod
Veamos cómo crear un archivo de manifiesto para desplegar un pod mediante un archivo de manifiesto YAML. El ejemplo despliega una web de contenido estático.
Archivo pod-dotnet2019.yaml
apiVersion: v1
kind: Pod
metadata:
name: dotnet2019
spec:
containers:
- name: dotnet2019
image: ualmtorres/dotnet2019web:v0Desplegaremos el pod con kubectl con este comando:
$ kubectl apply -f pod-dotnet2019.yamlSi contamos con una URL para el manifiesto también lo podemos desplegar haciendo referencia a la URL:
$ kubectl apply -f https://gist.githubusercontent.com/ualmtorres/c6d0052dacd386c3dd01e57ad06dedc5/raw/e3cb7b828c21f6ebe0daa459e37d1578af892ce6/DotNetAlmeria2019-pod-dotnet2019.yamlEsto creará un pod denominado dotnet2019 en el namespace default de nuestro cluster Kubernetes.
Para ver la aplicación de forma provisional haremos un port forward entre el pod y nuestro equipo local con
$ kubectl port-forward dotnet2019 83:80Al abrir un navegador en nuestro equipo en localhost:83 accederemos a la web desplegada.
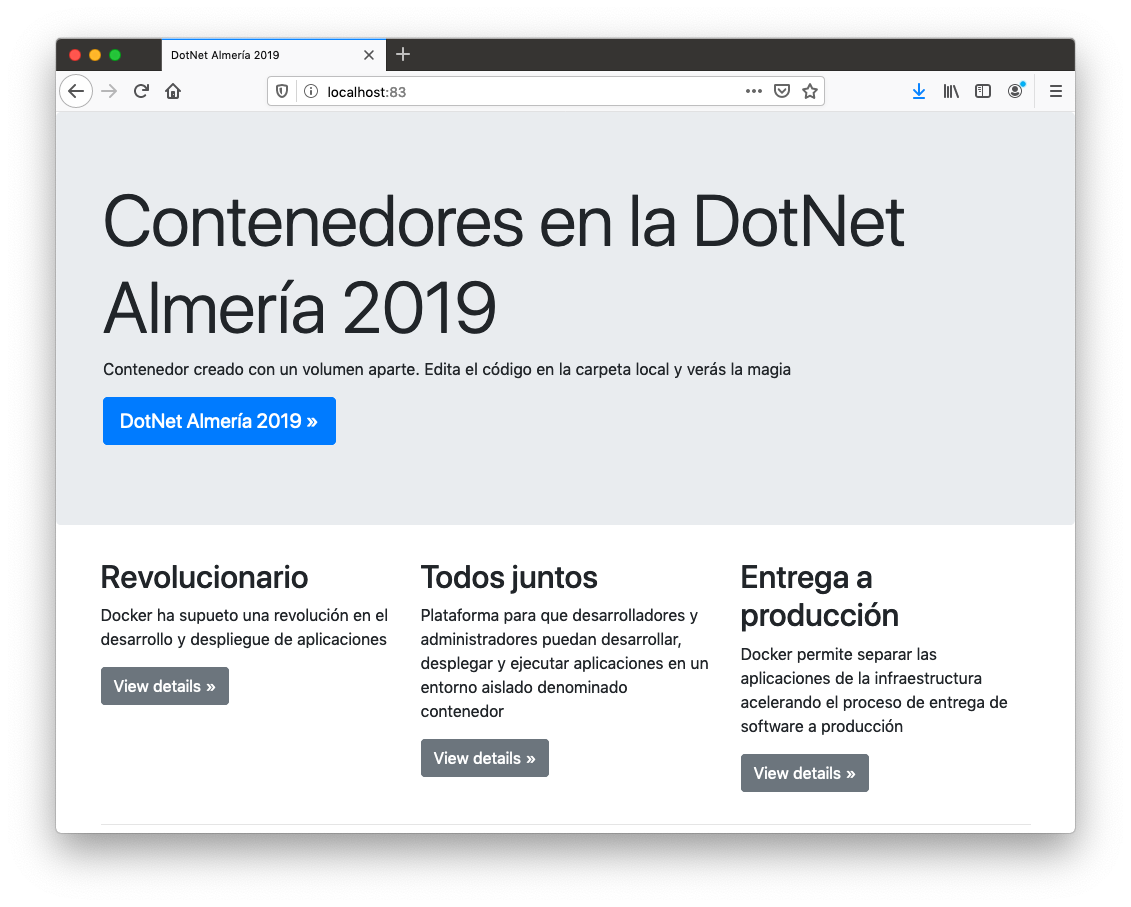
Si ahora queremos actualizar el pod con una nueva versión de la aplicación, basta con modificar el manifiesto YAML con la nueva imagen y volver a aplicar los cambios. Para ilustrar esto, modifiquemos la versión del manifiesto anterior a la imagen ualmtorres/dotnet2019web:v1 en lugar de la version v0. La nueva versión tiene los botones en verde.
La nueva versión del manifiesto quuedaría así:
apiVersion: v1
kind: Pod
metadata:
name: dotnet2019
spec:
containers:
- name: dotnet2019
image: ualmtorres/dotnet2019web:v1 (1)| 1 | Nueva imagen a desplegar |
Una vez guardados los cambios en el archivo de manifiesto, aplicaríamos los cambios con
$ kubectl apply -f pod-dotnet2019.yamlEsto hará que se descargue la nueva imagen, se cree un nuevo pod con la nueva imagen y se elimine el pod que estaba sirviendo. Una vez finalizado ese proceso ya estará disponible la nueva versión de la aplicación en la misma URL:
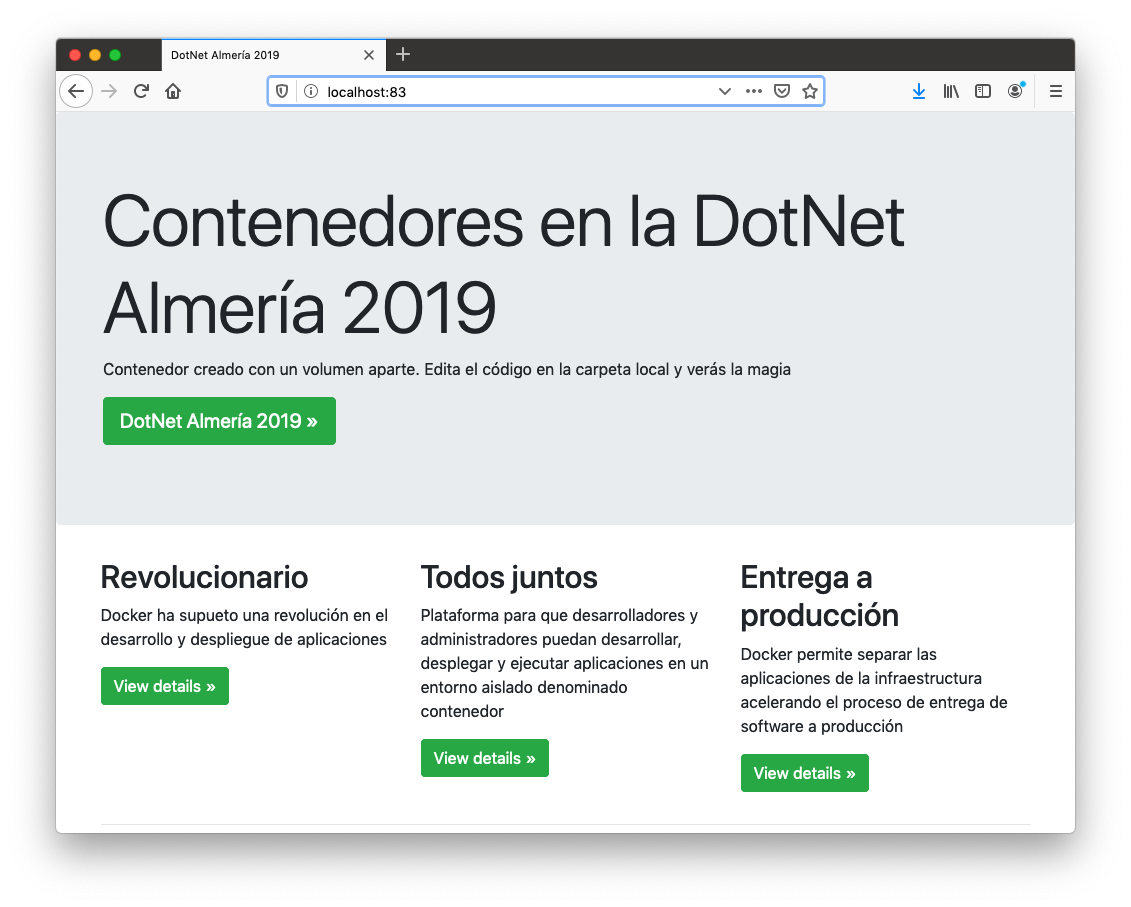
8.2. Despliegue de un Deployment
Normalmente no desplegaremos Pods. En su lugar desplegaremos Deployments. En ellos podremos incluir contenedores con imágenes diferentes para que puedan trabajar de forma coordinada. Un ejemplo habitual es el de frontend y backend. En la espeficación de los contenedores indicaremos además de la imagen de partida, número de réplicas, recursos solicitados (p.e. cantidad de RAM, porcentaje de CPU, …). Esto, además de desacoplar frontend y backend, desde el punto de vista de la escalabilidad, permite escalar frontend y backend de forma independiente.
|
Un archivo de Deployment proporciona una forma declarativa de creación de Pods y ReplicaSets. En el archivo de Deployment se especifica el estado deseado. |
Para ilustrar el despliegue de una aplicación mediante archivos YAML vamos a desplegar una aplicación de ejemplo que consuma del servicio jsonproducer creado anteriormente. Se trata de un ejemplo muy sencillo de un entorno frontend-backend con un funcionamiento independiente.
|
Recordemos que en la sección Ejemplo de escalado de una aplicación habíamos creado previamente un Deployment para |
Vamos a crear un archivo de Deployment denominado json-reader-deployment.yaml. Este archivo básicamente contiene entre otros, el nombre de despliegue, el selector que usa el despliegue para seleccionar los pods que forman parte del despliegue, la etiqueta que usan los pods para ser agrupados y formar parte del mismo Deployment, número de réplicas y la imagen usada para crear el contenedor de cada pod.
apiVersion: apps/v1
kind: Deployment (1)
metadata:
name: jsonreader (2)
namespace: default (3)
labels:
app: jsonreader (4)
spec:
revisionHistoryLimit: 2 (5)
strategy:
type: RollingUpdate (6)
replicas: 2 (7)
selector:
matchLabels:
app: jsonreader (8)
template: (9)
metadata:
labels: (10)
app: jsonreader
spec:
containers:
- name: jsonreader (11)
image: ualmtorres/jsonreader:v0 (12)
ports:
- name: http
containerPort: 80 (13)| 1 | Tipo de recurso a desplegar |
| 2 | Nombre del despliegue |
| 3 | Namespace de despliegue |
| 4 | Etiqueta que usar el Deployment para ser luego seleccionado por otro objeto Kubernetes (p.e. Service). |
| 5 | Número de versiones almacenadas para poder deshacer despliegues fallidos |
| 6 | Tipo de estrategia de actualización |
| 7 | Número de réplicas del despliegue |
| 8 | Selector que define cómo el Deployment encuentra los Pods a gestionar, que coincide con el definido en la plantilla (template) del pod |
| 9 | Zona (plantilla) de definición del pod |
| 10 | Etiquetas asignadas a los pods y que les permitirán ser seleccionados para formar parte de un Deployment |
| 11 | Prefijo usado para los pods |
| 12 | Imagen base para los contenedores de la aplicación |
| 13 | Puerto por el que la aplicación sirve originalmente sus datos |
|
La estrategia de despliegue ( |
El despliegue se realiza con kubectl con el comando siguiente
$ kubectl apply -f json-reader-deployment.yamlAl crear el despliegue, se procederá a descargar la imagen y se pasarán a crear los dos pods indicados para este despliegue. Podemos ver los pods creados con el comando siguiente comprobando que efectivamente se creado los dos pods jsonreader que exigía el despliegue.
Podemos ver el despliegue con el comando siguiente
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
jsonproducer 1/1 1 1 22h
jsonreader 2/2 2 2 21hTambién podemos ver los ReplicaSets creados por los despliegues
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
jsonproducer-7769d76894 1 1 1 22h
jsonreader-86699d9f94 2 2 2 22hLos pods los podemos ver junto con sus etiquetas con el parámetro --show-labels
$ kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
jsonproducer-7769d76894-ss5qh 1/1 Running 1 22h pod-template-hash=7769d76894,run=jsonproducer
jsonreader-86699d9f94-khfzh 1/1 Running 1 22h app=jsonreader,pod-template-hash=86699d9f94
jsonreader-86699d9f94-lrvpt 1/1 Running 1 22h app=jsonreader,pod-template-hash=86699d9f94Ahora podríamos ver a cualquiera de los pods de jsonreader haciendo port forward a nuestro equipo.
$ kubectl port-forward jsonreader-86699d9f94-lrvpt 84:80Este sería su resultado en un navegador
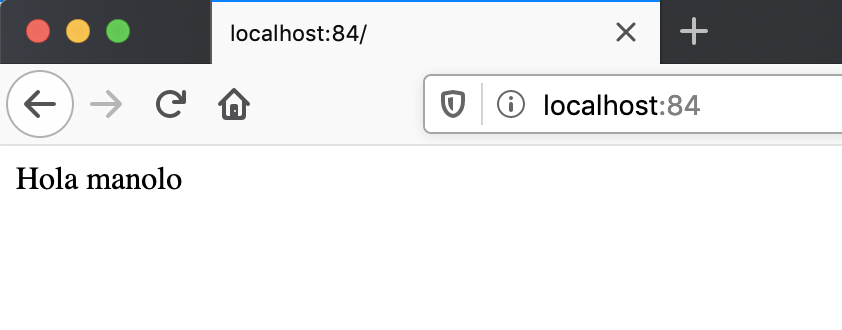
|
Hacer hincapie en que se puede ver funcionando correctamente este ejemplo porque ya se creó previamente en la sección Ejemplo de escalado de una aplicación el servicio para |
Puedes encontrar un ejemplo más completo de Deployment con un front-end más elaborado que consume de una API que proporciona calificaciones de estudiantes.
Sin embargo, vemos que el frontend no puede recuperar los datos del backend. Esto se debe a que aún no hay definido un servicio. En la siguiente sección encontraremos la solución a ese problema.
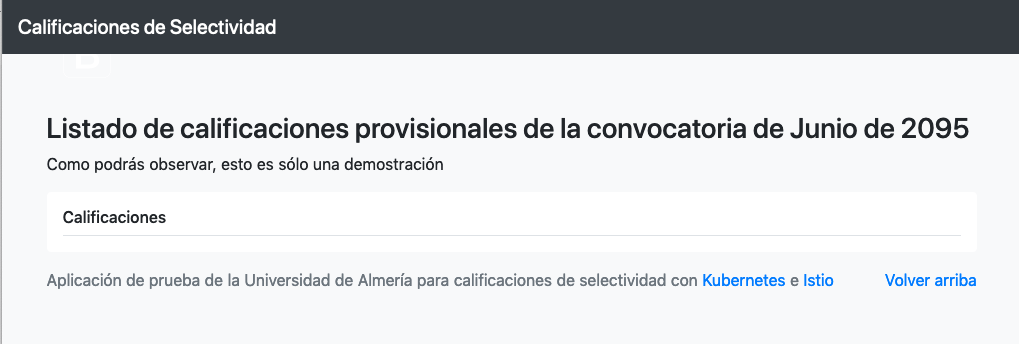
|
Los servicios gestionan el descubrimiento y enrutado entre pods dependientes (p.e. frontend y backend) |
8.3. Despliegue de un Service
Un Service es una abstracción que define una agrupación de Pods y una política de acceso a ellos. El conjunto de Pods al que se dirige un Servicio están determinados por un selector.
En la sección Ejemplo de escalado de una aplicación habíamos creado un servicio directamente al hacer kubectl expose deployment jsonproducer --type=NodePort. A continuación vamos a ver cómo podemos crear ese servicio mediante un manifiesto YAML.
Vamos a crear un archivo de Servicio denominado json-reader-service.yaml. Este archivo básicamente contiene entre otros el nombre de servicio, el tipo del servicio (ClusterIP, NodePort, …), el puerto de acceso a los pods del despliegue y el selector que identifica al despliegue con el que se corresponde el servicio creado.
apiVersion: v1
kind: Service (1)
metadata:
name: jsonreader (2)
namespace: default (3)
spec:
type: NodePort (4)
ports:
- name: http
port: 80 (5)
targetPort: http
selector:
app: jsonreader (6)| 1 | Tipo de recurso a desplegar |
| 2 | Nombre del servicio |
| 3 | Namespace de despliegue |
| 4 | Tipo de servicio. NodePort hará que el servicio esté disponible en la IP de los nodos en los que estén los pods y un puerto aleatorio entre 30000 y 32767 |
| 5 | Puerto en el que los pods están sirviendo su contenido |
| 6 | Etiqueta que usa el servicio para localizar al Deployment. Buscará un valor coincidente en la etiqueta labels del Deployment. |
El despliegue se realiza con kubectl con el comando siguiente
$ kubectl create -f json-reader-service.yamlEl despliegue nos permitirá acceder a la aplicación en un puerto en el rango 30000-32767. En este caso ha tocado el 31976
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
jsonproducer NodePort 10.105.30.95 <none> 80:30228/TCP 22h
jsonreader NodePort 10.99.85.2 <none> 80:31976/TCP 22h
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 22hPara poder acceder al servicio pediremos a Minikube que nos lo muestre.
$ minikube service jsonreaderEsto hará que se abra un navegador con la aplicación jsonreader que simplemente lee el JSON y presenta un saludo sencillo.
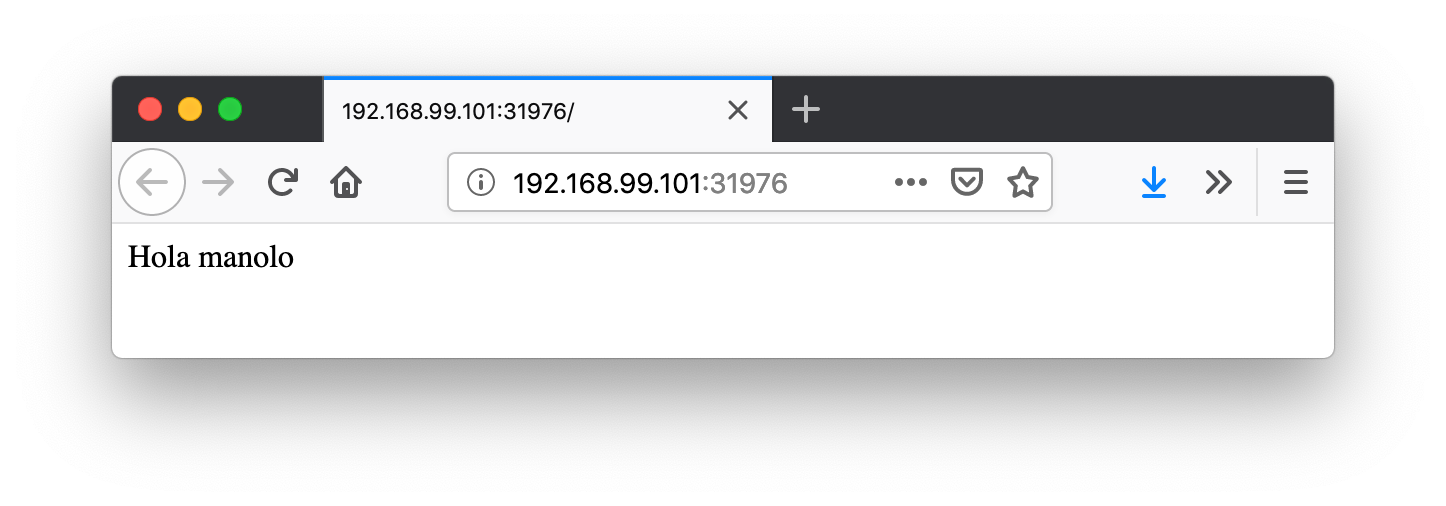
También podemos usar el Kubernetes Dashboard para mostrar información de interés sobre este despliegue, viendo como el Deployment de jsonreader se ha incorporado a la lista de despliegues disponibles en el cluster, así como los Pods, ReplicaSets y Services, como muestran las figuras siguientes.
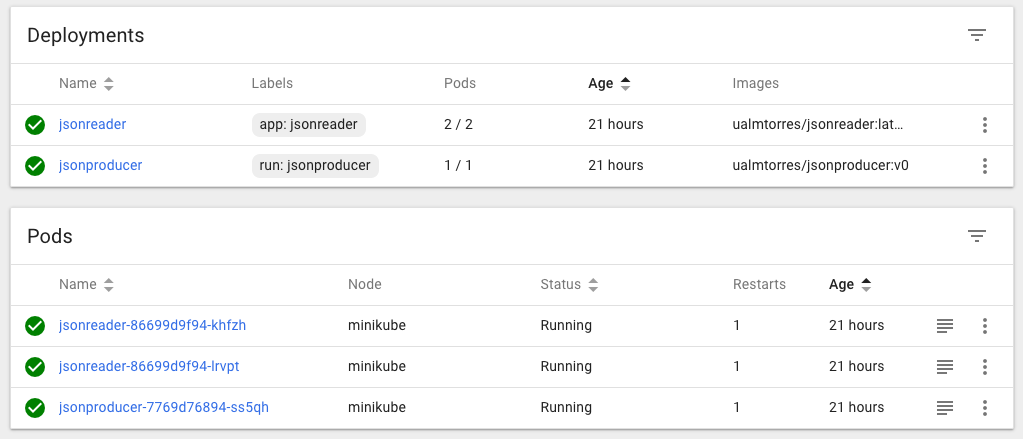
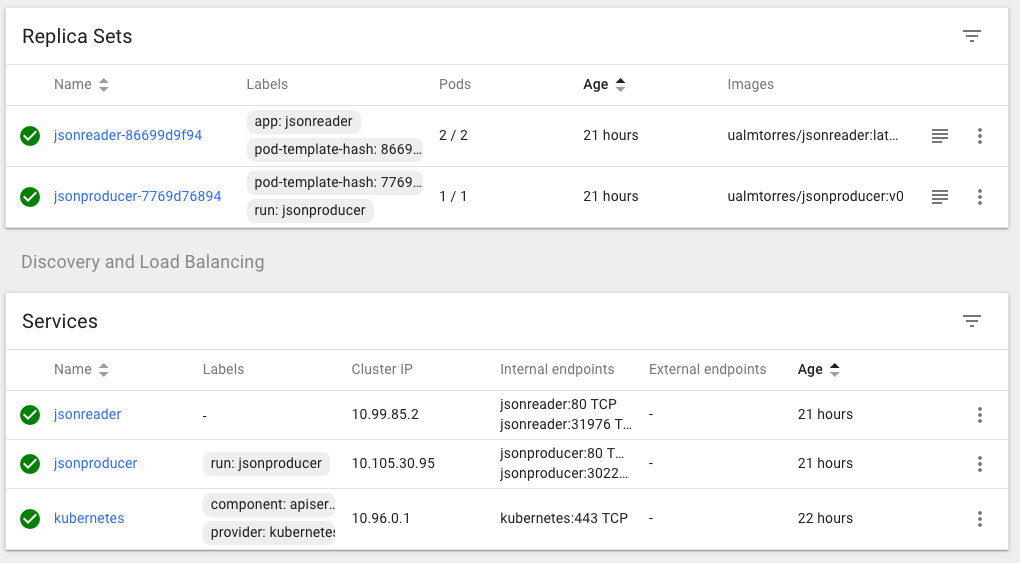
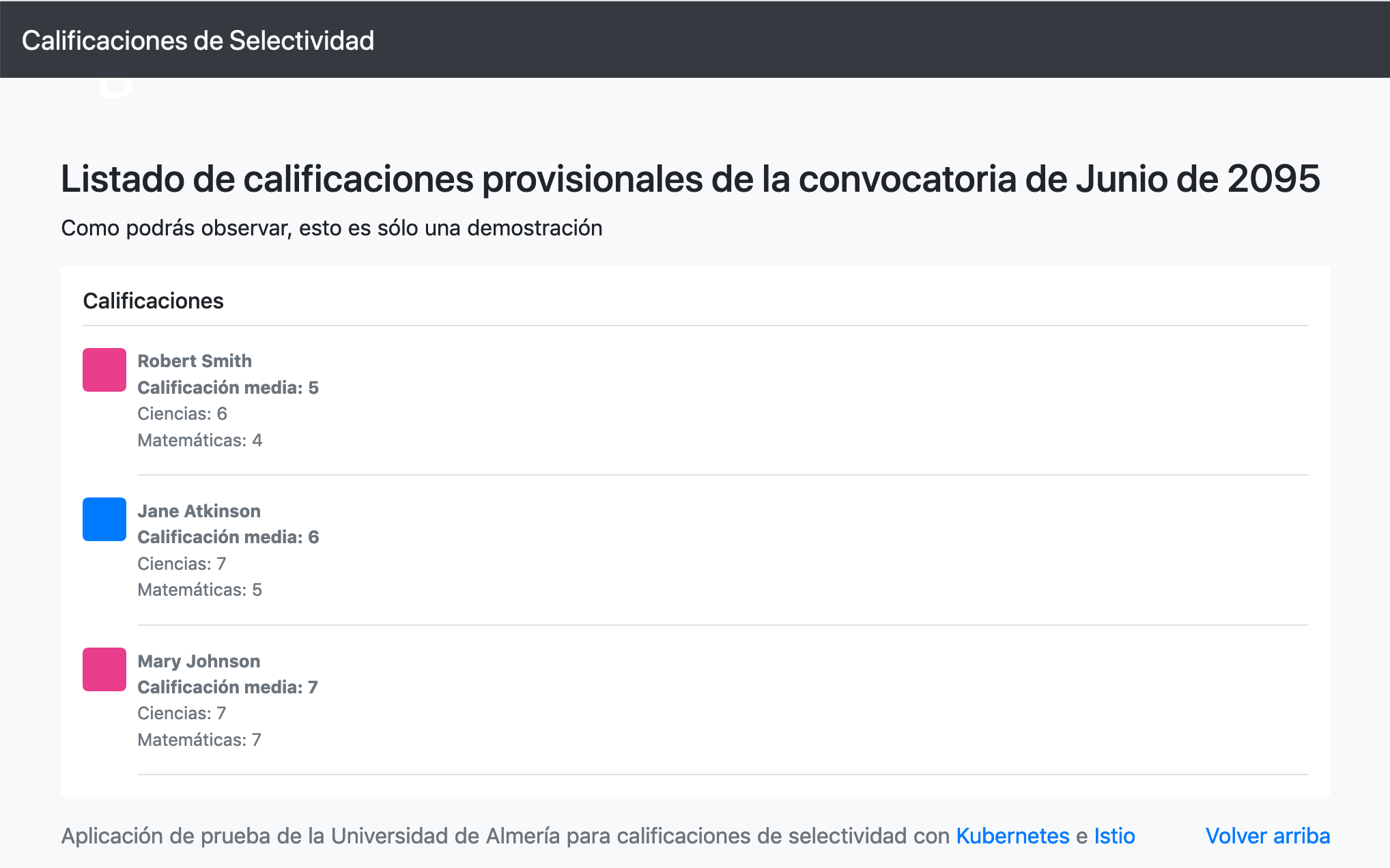
Puedes encontrar un ejemplo más completo de Service que completa el Deployment de la sección anterior. Recordemos que el frontend no podía obtener la lista de calificaciones que ofrecía la API. Esto se debía a que se había desplegado el Deployment de la API, pero no se había desplegado su Service, que es lo que le da visibilidad.
Al desplegar el servicio del backend ya podremos ver que el frontend ya sí puede acceder a los datos que genera la API.
8.4. Despliegue de ConfigMaps
Tal y como comentamos anteriormente en la sección ConfigMaps, los objetos ConfigMap permiten almacenar datos no sensibles en forma de clave valor. Un uso habitual de los ConfigMap es para inicialización de variables de entorno.
Antes de comenzar a usar ConfigMaps con variables de entorno, veamos cómo establecer variables de entorno. El ejemplo siguiente muestra un manifiesto YAML que crea un pod e inicializa dos variables de entorno (NOMBRE y APELLIDOS)
apiVersion: v1
kind: Pod
metadata:
name: configmap-env
spec:
containers:
- name: php-apache
image: php:7-apache
env:
- name: NOMBRE
value: Manolo
- name: APELLIDOS
value: TorresEl código siguiente muestra cómo lanzamos el manifiesto YAML para configurar las variables de entorno:
$ kubectl apply -f configmap-env.yamlUna vez que el pod esté en ejecución podremos abrir una sesión interactiva en él con
$ kubectl exec -it configmap-env /bin/bashUna vez dentro del contenedor del pod podremos mostrar las variables de entorno
$ echo $NOMBRE
$ echo $APELLIDOSUna vez hecho esto haremos el mismo ejemplo pero configurando los valores a través de un ConfigMap. Una vez creado el ConfigMap, habrá que acceder a sus pares clave-valor para asignarlo a las variables del entorno en el contenedor de destino.
El manifiesto YAML siguiente crea un objeto ConfigMap con dos pares clave-valor y un objeto Pod que accede al ConfigMap para inicializar dos variables de entorno.
apiVersion: v1
kind: ConfigMap
metadata:
name: myconfigmap (1)
data:
nombre: Manolo (2)
apellidos: Torres
---
apiVersion: v1
kind: Pod
metadata:
name: configmap-pod
spec:
containers:
- name: configmap-container
image: php:7-apache
env:
- name: NOMBRE
valueFrom: (3)
configMapKeyRef: (4)
name: myconfigmap (5)
key: nombre (6)
- name: APELLIDOS
valueFrom:
configMapKeyRef:
name: myconfigmap
key: apellidos| 1 | Nombre del objeto ConfigMap para poder ser usado posteriormente |
| 2 | Configuración de pares clave-valor en el ConfigMap |
| 3 | Acceso de un valor almacenado |
| 4 | Acceso a un un ConfigMap |
| 5 | Nombre del ConfigMap a usar |
| 6 | Clave del ConfigMap a leer |
El código siguiente muestra cómo lanzamos el manifiesto YAML para configurar las variables de entorno:
$ kubectl apply -f configmap-pod.yamlUna vez que el pod esté en ejecución podremos abrir una sesión interactiva en él con
$ kubectl exec -it configmap-env /bin/bashUna vez dentro del contenedor del pod podremos mostrar las variables de entorno
$ echo $NOMBRE
$ echo $APELLIDOS8.5. Despliegue de Secrets
Como comentamos anteriormente en la sección Secrets, los objetos Secret se usan para almacenar información sensible, como contraseñas, tokens OAuth y claves ssh. No obstante, los datos de los objetos Secret no están cifrados. Están codificados en base64 y pueden hacerse visibles fácilmente.
Para ilustrar el uso de Secrets veamos el manifiesto de creación de un pod con MySQL sin y con secretos.
El manifiesto siguiente crea un pod MySQL al que se le pasa la variable de entorno MYSQL_ROOT_PASSWORD durante su inicialización para la contraseña del root. En este ejemplo, el valor de la variable de entorno de la contraseña del root es pasada en el propio manifiesto
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-sin-secrets
spec:
selector:
matchLabels: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql-sin-secrets
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: password
ports:
- containerPort: 3306El manifiesto anterior lo lanzamos con
$ kubectl apply -f mysql-sin-secrets.yamlA continuación vamos a modificar el manifiesto anterior para hacer uso de objetos Secret.
Kubernetes guarda los secretos en base64. Por tanto, los valores que vayamos a almacenar en los pares clave-valor de un secreto tendrán que estar en base64.
Para codificar en base64 el valor password que utilizamos en el ejemplo anterior para contraseña del root, ejecutaremos el comnando siguiente desde la línea de comandos:
$ echo -n 'password' | base64Esto devolverá la cadena cGFzc3dvcmQ=, que corresponde a la cadena password en base64. Este valor codificado será el que usaremos para la creación del Secret.
A continuación crearemos el manifiesto YAML secret-password.yaml que inicializa un objeto Secret.
apiVersion: v1
kind: Secret
metadata:
name: mysqlpassword
type: Opaque
data:
password: cGFzc3dvcmQ=Lanzamos la creación del Secret con kubectl:
kubectl apply -f secret-password.yamlPor último, creamos el manifiesto YAML que inicializa un pod MySQL que lee del Secret creado la contraseña del usuario root para inicializar el pod correctamente.
apiVersion: apps/v1
kind: Deployment
metadata:
name: initdb
spec:
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql-con-secrets
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysqlpassword
key: password
ports:
- containerPort: 3306Este manifiesto lo lanzaremos con kubectl:
$ kubectl apply -f mysql-con-secrets.yaml9. HPA. Horizontal Pod Autoscaler
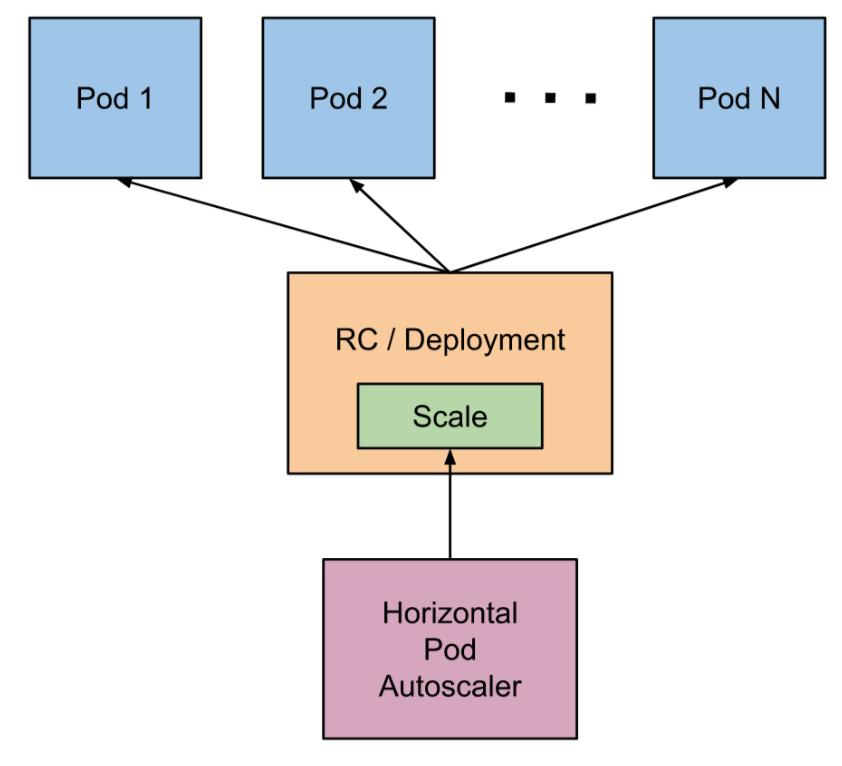
El Horizontal Pod Autoscaler, o HPA pasa simplificar, escala de forma automática el número de réplicas de un pod en función de la observación de métricas de los pods (p.e. el uso de la CPU).
De forma escueta podemos resumir de esta forma su funcionamiento:
-
En su definición se fija un mínimo y máximo de réplicas de un deployment
-
En su definición se definen las condiciones de stress (p.e. porcentaje de uso de la CPU)
-
HPA consulta cada 15s las métricas de uso (CPU, RAM, …) de cada pod
-
Ante stress HPA escala hacia arriba
-
HPA escala hacia abajo tras un periodo de 5 minutos sin stress
A continuación se muestran la redefinición de los Deployment de los ejemplos de la API y frontend del ejemplo de las calificaciones especificando una petición de CPU y memoria para cada pod.
Archivo deployment-api.yaml indicando límites de CPU y memoria:
apiVersion: apps/v1
kind: Deployment
metadata:
name: selectividad-api
namespace: default
labels:
app: selectividad-api
spec:
revisionHistoryLimit: 2
strategy:
type: RollingUpdate
selector:
matchLabels:
app: selectividad-api
template:
metadata:
labels:
app: selectividad-api
spec:
containers:
- name: selectividad-api
image: ualmtorres/selectividad-api:v2
ports:
- name: http
containerPort: 80
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256MiArchivo deployment-front.yaml indicando límites de CPU y memoria:
apiVersion: apps/v1
kind: Deployment
metadata:
name: selectividad-front
namespace: default
labels:
app: selectividad-front
spec:
revisionHistoryLimit: 2
strategy:
type: RollingUpdate
selector:
matchLabels:
app: selectividad-front
template:
metadata:
labels:
app: selectividad-front
spec:
containers:
- name: selectividad-front
image: ualmtorres/selectividad-front:v2
ports:
- name: http
containerPort: 80
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi|
La petición de CPU es relativa a unidades teniendo en cuenta lo siguiente:
Las peticiones se hacen en miliCPUs o en fracciones decimales de CPU. Así una petición de 100m y de 0.1 representan la misma cantidad de CPU solicitada. La unidad mínima solicitada es 1m (1 miliCPU). |
|
También es posible limitar los recursos de RAM asignados a un contenedor. Consultar la documentación oficial sobre la asignación de recursos de RAM a un contenedor para más información. |
A continuación se muestra el manifiesto que crea un servicio para cada deployment.
apiVersion: v1
kind: Service
metadata:
name: selectividad-api
spec:
type: ClusterIP
ports:
- port: 80
selector:
app: selectividad-api
---
apiVersion: v1
kind: Service
metadata:
name: selectividad-front
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: selectividad-frontUna vez definidos los objetos Deployment y sus Service correspondientes, pasamos a crear el HPA que monitorizará el uso de recursos de los contenedores y solicitará su autoescalado en función del uso de los recursos. En este caso, y para poder ver en acción fácilmente el autoescalado en acción, fijamos que a partir del 15% de uso de la CPU se soliten la creación de nuevos pods. También se indica que el intervalo de escalado esté entre 1 y 10 réplicas según demanda.
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: selectividad-api
spec:
scaleTargetRef:
apiVersion: apps/v1beta1
kind: Deployment
name: selectividad-api
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 15
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: selectividad-front
spec:
scaleTargetRef:
apiVersion: apps/v1beta1
kind: Deployment
name: selectividad-front
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 15Podemos acceder al estado y condiciones del autoescalado con el comando siguiente.
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
selectividad-api Deployment/selectividad-api 1%/15% 1 10 1 5m
selectividad-front Deployment/selectividad-front 1%/15% 1 10 1 5m9.1. Prueba de stress de autoescalado
Apache Benchmark es una herramienta útil para realizar pruebas de carga. A continuación se muestra cómo hacer una prueba de carga con
-
100.000 peticiones totales
-
100 peticiones simultáneas
$ ab -n 100000 -c 100 http://selectividad-front.default.192.168.66.253.xip.io/|
Este ejemplo ha sido realizado en un cluster Kubernetes que gestionamos con Rancher. Al servicio de frontend le hemos creado un ingress de tipo load balancer para poder acceder al cluster desde fuera con un nombre DNS. |
La figura siguiente ilustra varias capturas de cómo ha ido adaptándose el número de pods a la demanda a lo largo de la prueba de carga. Hemos usado colores naranja, rojo y azul para ilustrar el estado de stress y la respuesta elástica con el número de pods en distintos estados que hemos ido capturando durante la prueba de carga.
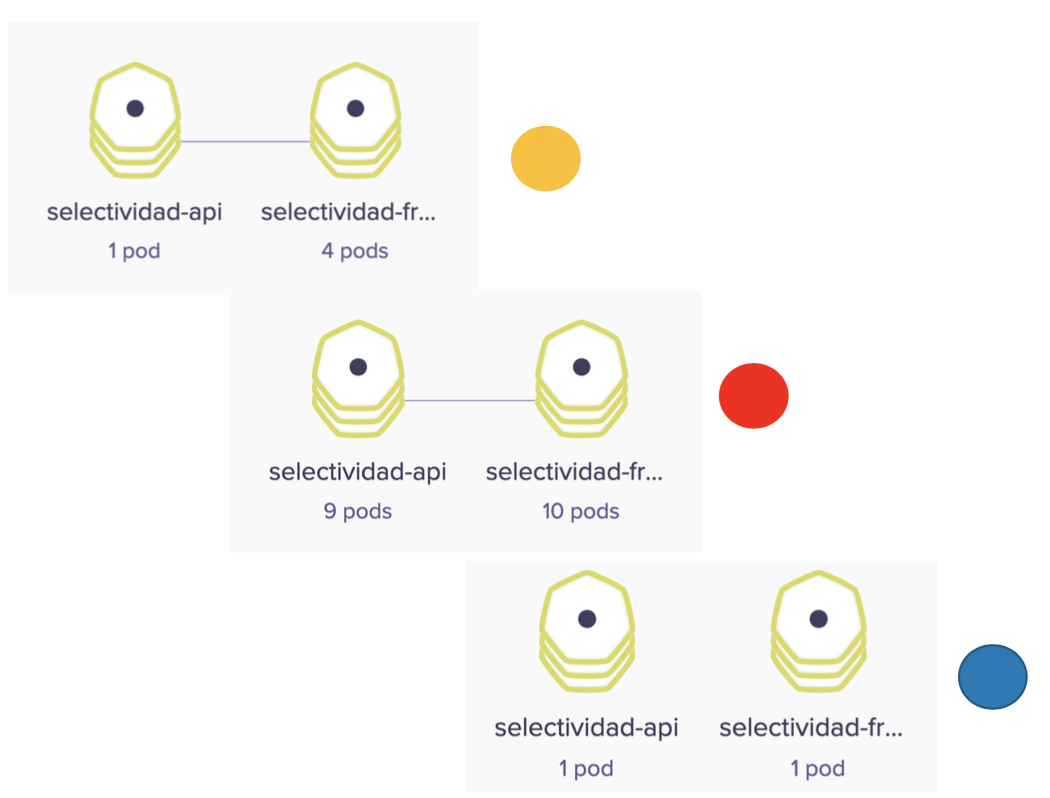
La figura siguiente ilustra el estado del objeto HPA con el comando
$ kubectl get horizontalpodautoscalers.autoscaling --watch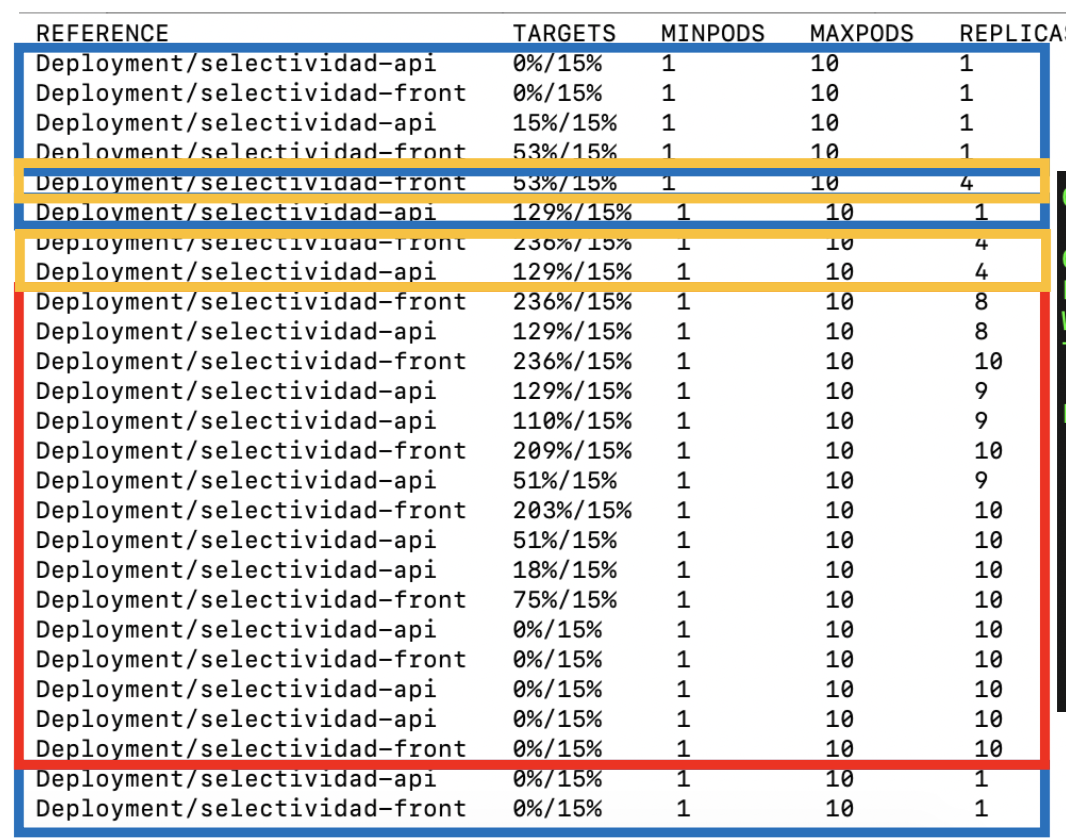
10. Almacenamiento en volúmenes
El almacenamiento en contenedores es efímero. Una vez que el contenedor es eliminado también son eliminados sus archivos. Pero además, cuando un contenedor falla, kubelet lo reiniciará con un estado limpio habiéndose perdido todo lo que había en sus archivos.
Kubernetes cuenta con una gran cantidad de tipos de volúmenes. Los hay de almacenamiento local, almacenamiento en el sistema de archivos de los nodos de Kubernetes, Ceph, Gluster, NFS y almacenamiento cloud, como en Azure, Azure, Google y OpenStack Cinder, por citar algunos. También permite volúmenes configmap y secret, útiles para el compartir entre pods datos de configuración o información sensible, como contraseñas. En cualquier caso, los volúmenes son montados por los pods y accederían a sus datos.
10.1. Volúmenes emptyDir
Se trata de volúmenes que se crean al asignar un pod a un nodo. Su contenido se mantiene en el nodo hasta que el contenedor sea eliminado. Su contenido se mantiene aunque el contenedor sea destruido o eliminado.
De forma predeterminada, los volúmenes emptyDir son almacenados en el medio de almacenamiento prederminado del nodo (HD, SSD, NAS, …). No obstante, se puede definir este tipo de volúmenes como volátiles configurando la propiedad emptyDir.medium como Memory y Kubernetes lo montará como un sistema de archivos RAM, lo que puede ser muy útiles para cachés.
Este tipo de contenedores se suele usar para situaciones en las que queremos compartir datos entre varios contenedores en un pod o cachés.
El manifiesto siguiente crea un pod con Redis usando un volumen emptyDir. El volumen se monta en el directorio /data del contenedor, que es el directorio predeterminado de almacenamiento de la imagen de Redis.
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
volumeMounts: (1)
- name: redis-storage (2)
mountPath: /data (3)
volumes: (4)
- name: redis-storage (5)
emptyDir: {} (6)| 1 | Montaje de un volumen en el contenedor |
| 2 | Nombre del volumen a montar |
| 3 | Ruta del contenedor donde se va a montar el volumen |
| 4 | Definición del volumen |
| 5 | Nombre asignado al volumen |
| 6 | Tipo de volumen |
A continuación ya podremos desplegar este pod con un volumen emptyDir usando kubectl
$ kubectl apply -f redis.yaml10.2. Volúmenes hostPath
Un volumen hostPath monta en el contenedor un archivo o un directorio del sistema de archivos del nodo en el que está ejecutándose el pod.
|
Este tipo de volúmenes no es una solución buena para clusters Kubernetes con varios nodos, ya que no se guardarían los mismos datos en cada nodo. |
El ejemplo siguiente muestra un manifiesto para la creación de un pod con un contenedor Apache que monta un volumen hostPath. El contenedor monta ese volumen en la carpeta de publicación del contenedor Apache (/usr/local/apache2/htdocs/).
apiVersion: v1
kind: Pod
metadata:
name: hostPathContainer
spec:
containers:
- image: nginx
name: nginx-hostPath
volumeMounts:
- mountPath: /vol-hostPath
name: myvolume
volumes:
- name: myvolume
hostPath:
path: /data/pv|
Crear volúmenes Es posible controlar la creación del volumen para montar un archivo o directorio del nodo sólo en aquellos casos en los que previamente exista dicho archivo o directorio. Para ello, tenemos que crear el volumen con
Para más información sobre cómo limitar y configurar el uso de |
10.3. Volúmenes con Openstack Cinder
Podemos montar volúmenes OpenStack Cinder en pods Kubernetes. Previamente tendremos que haber configurado el cluster Kubernetes con OpenStack como proveedor cloud. Los volúmenes Cinder son volúmenes externos al cluster Kubernetes y son persistentes, de forma que su contenido se mantiene después de la eliminación de los pods que lo tengan montado.
Para este ejemplo partimos de un cluster Kubernetes gestionado con Rancher. En la configuración del archivo YAML del cluster añadiremos lo siguiente:
cloud_provider:
name: "openstack"
openstackCloudProvider:
block_storage:
ignore-volume-az: true
trust-device-path: false
global:
auth-url: "http://www.xxx.yyy.zzz:5000/v3/" (1)
domain-name: "xxx" (2)
tenant-id: "xxx" (3)
username: "xxx" (4)
load_balancer:
create-monitor: false
manage-security-groups: false
monitor-max-retries: 0
subnet-id: "xxx" (5)
use-octavia: false
metadata:
request-timeout: 0| 1 | IP o nombre DNS del servicio Keystone de identificación |
| 2 | Nombre de dominio (p.e. default) |
| 3 | id del proyecto que proporciona los recursos OpenStack a Kubernetes |
| 4 | Nombre de usuario |
| 5 | id de la subred a la que se conectarán el balanceador que proporciona acceso a los servicios de tipo loadbalancer |
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: cinder-sc
provisioner: kubernetes.io/cinder
parameters:
availability: nova$ kubectl apply -f cinder-storageclass.yaml$ kubectl get storageclasses.storage.k8s.io
NAME PROVISIONER AGE
cinder-sc kubernetes.io/cinder 15skind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: cinder-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 9Gi # pass here the size of the volume
storageClassName: cinder-sc$ kubectl apply -f cinder-persistentvolumeclaim.yaml$ kubectl get persistentvolumeclaims
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
cinder-pvc Bound pvc-3688b17d-0de1-11ea-945c-fa163e416ffb 9Gi RWO cinder-sc 15sapiVersion: apps/v1
kind: Deployment
metadata:
name: apache-cinder
spec:
selector:
matchLabels:
app: apache
template:
metadata:
labels:
app: apache
spec:
containers:
- name: apache
image: httpd
volumeMounts:
- mountPath: /usr/local/apache2/htdocs
name: cinder-vol
ports:
- containerPort: 80
volumes:
- name: cinder-vol
persistentVolumeClaim:
claimName: cinder-pvc$ kubectl apply -f cinder-apache-pvc.yaml$ kubectl get pods
NAME READY STATUS RESTARTS AGE
apache-cinder-54d6c66cf8-djv76 1/1 Running 0 15s$ sudo kubectl port-forward apache-cinder-54d6c66cf8-djv76 81:80
Forwarding from 127.0.0.1:81 -> 80
Forwarding from [::1]:81 -> 80
$ kubectl exec -it apache-cinder-54d6c66cf8-djv76 /bin/bashroot@apache-cinder-54d6c66cf8-djv76:/usr/local/apache2# echo "<h1>Volumen Cinder</h1>" > htdocs/index.html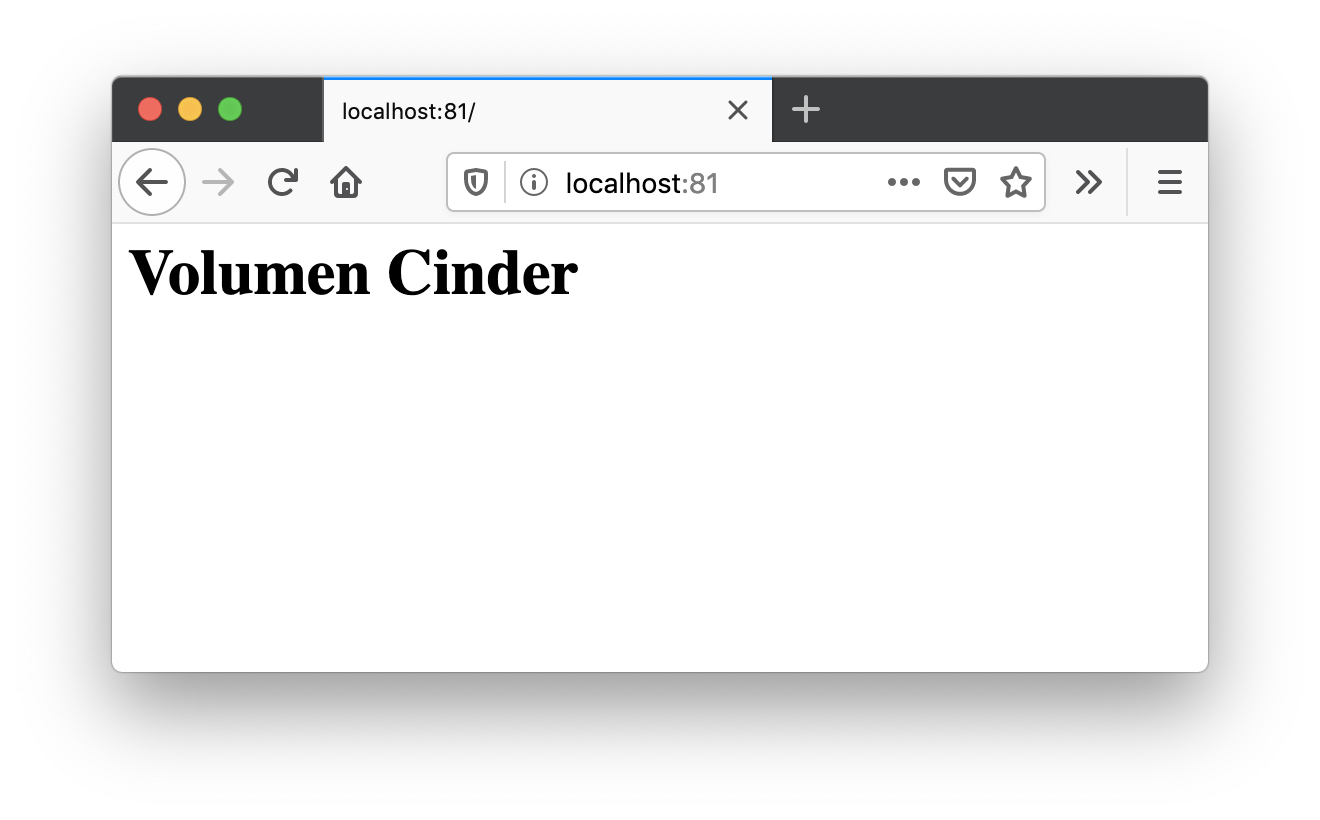
$ kubectl delete -f cinder-apache-pvc.yaml$ kubectl apply -f cinder-apache-pvc.yaml$ kubectl get pods
NAME READY STATUS RESTARTS AGE
apache-cinder-54d6c66cf8-zx92w 1/1 Running 0 102ssudo kubectl port-forward apache-cinder-54d6c66cf8-zx92w 81:8010.4. Volúmenes NFS. Openstack Manila
Kubernetes permite montar shares NFS existentes en un pod. Los volúmenes NFS son volúmenes externos al cluster Kubernetes y son persistentes, de forma que su contenido se mantiene después de la eliminación de los pods que lo tengan montado.
Para este ejemplo usaremos Openstack Manila como servidor NFS. Para los ejemplos ya tenemos creado un share,. disponible en en la ruta /var/lib/manila/mnt/share-2e653a46-bc6a-4fc3-83d3-d144554113e1 del servidor 192.168.64.17
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle
nfs:
path: /var/lib/manila/mnt/share-2e653a46-bc6a-4fc3-83d3-d144554113e1
server: 192.168.64.17$ kubectl apply -f nfs-persistentvolume.yamlapiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
storageClassName: ""
volumeName: nfs-pv$ kubectl apply -f nfs-persistentvolumeclaim.yamlkubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/nfs-pv 10Gi RWX Recycle Bound default/nfs-pvc 3m36s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/nfs-pvc Bound nfs-pv 10Gi RWX 3m35apiVersion: apps/v1
kind: Deployment
metadata:
name: apache-nfs
spec:
selector:
matchLabels:
app: apache
template:
metadata:
labels:
app: apache
spec:
containers:
- name: apache
image: httpd
volumeMounts:
- mountPath: /usr/local/apache2/htdocs
name: nfs-vol
ports:
- containerPort: 80
volumes:
- name: nfs-vol
persistentVolumeClaim:
claimName: nfs-pvcapiVersion: apps/v1
kind: Deployment
metadata:
name: www-vol
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- mountPath: /usr/share/nginx/html
name: nfs-vol
ports:
- containerPort: 80
volumes:
- name: nfs-vol
persistentVolumeClaim:
claimName: nfs-pvc$ kubectl apply -f nfs-apache-pvc.yaml
$ kubectl apply -f nfs-nginx-pvc.yaml$ kubectl get pods
NAME READY STATUS RESTARTS AGE
apache-nfs-5cb7d87b6f-jp774 1/1 Running 0 4m55s
nginix-nfs-58d6698d65-vfqkv 1/1 Running 0 4m54s$ sudo kubectl port-forward apache-nfs-5cb7d87b6f-jp774 82:80
Forwarding from 127.0.0.1:82 -> 80
Forwarding from [::1]:82 -> 80
$ sudo kubectl port-forward nginix-nfs-58d6698d65-vfqkv 83:80
Forwarding from 127.0.0.1:83 -> 80
Forwarding from [::1]:83 -> 80
kubectl exec -it apache-nfs-5cb7d87b6f-jp774 /bin/bashroot@apache-nfs-5cb7d87b6f-jp774:/usr/local/apache2# echo "<h1>Volumen NFS</h1>" > htdocs/index.html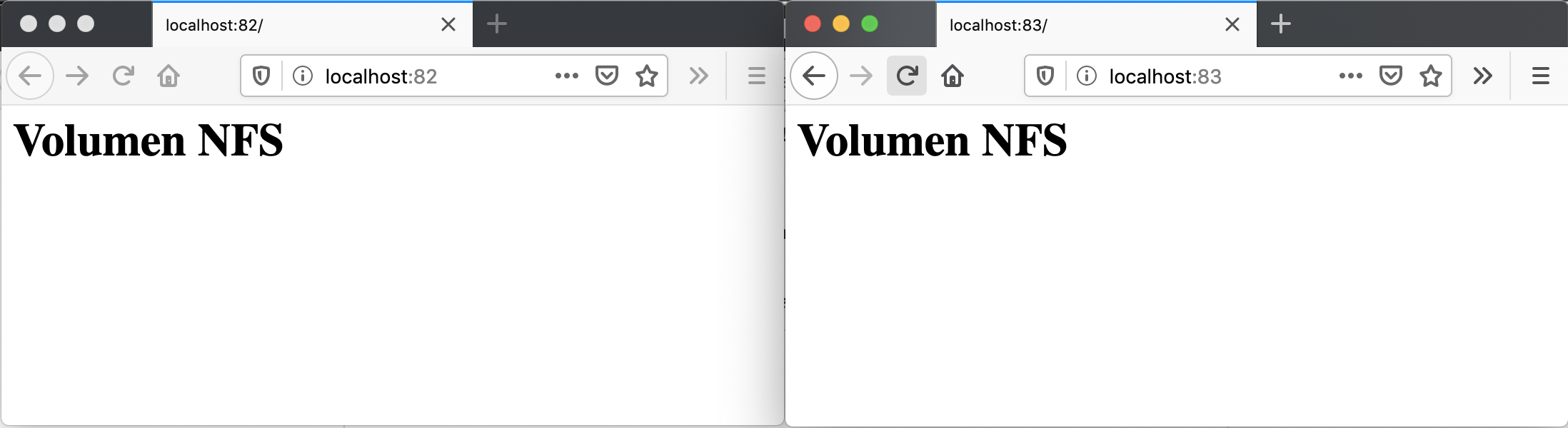
$ kubectl delete -f nfs-apache-pvc.yamlkubectl apply -f nfs-apache-pvc.yaml
deployment.apps/apache-nfs created$ kubectl get pods
NAME READY STATUS RESTARTS AGE
apache-nfs-5cb7d87b6f-2dzhr 1/1 Running 0 46s
nginix-nfs-58d6698d65-vfqkv 1/1 Running 0 16msudo kubectl port-forward apache-nfs-5cb7d87b6f-2dzhr 82:80
Forwarding from 127.0.0.1:82 -> 80
Forwarding from [::1]:82 -> 8011. Init Containers
Existen un tipo especial de contenedores denominados Init Containers que se ejecutan antes que el resto de contenedores de aplicación del pod. Este tipo de contenedores suelen dedicarse a realizar operaciones de incialización que no están presentes en la imagen de los otros contenedores del pod.
Para ilustrar el uso de Init Container supongamos que queremos tener disponibles distintos tipos de bases de datos MySQL para pruebas en desarrollo.. En función del proyecto en el que estemos trabajando queremos tener disponible una base de datos u otra (p.e. recursos humanos, espacios, expedientes, préstamos, …). Para ello, contaremos con varios scripts diferentes de inicialización de los distintos tipos de bases de datos que queremos configurar.
Para llevar a cabo ese caso práctico contaremos con:
-
URL donde se encuentra el script de inicialización de la base de datos.
-
ConfigMap que configura la URL del script con el que se va a inicializar la base de datos.
-
Secret el que se almacena la contraseña del usuario
root. -
Init Container que inicializa una imagen
busyboxcon un volumen donde descarga el script SQL que inicializa la BD. La URL de descarga del script la toma del ConfigMap. El script SQL se descarga con el nombreinit.sqlpara que sirva como script de inicialización del contenedor MySQL.La imagen
busyboxcontiene gran cantidad de utilidades Linunx incorporadas y nos va a ser muy útil para realizar la tarea de inicialización de la base de datos en su contenedor compañero de MySQL -
Contenedor que monta el volumen que ha inicializado el Init Container con el script SQL. Dicho volumen es montando en el directorio
/docker-entrypoint-initdb.dde la imagen MySQL. Como el script se llamainit.sql, al arrancar por primera vez el contenedor MySQL, se inicializará el contenedor con la base de datos elegida.
Esta configuración con Init Container permite la configuración a medida y sobre la marcha de una imagen MySQL sin necesidad de tener disponibles diferentes imágenes MySQL, cada una con su propia base de datos. En su puesto, lo que hacemos es cambiar en el ConfigMap la URL del script que inicializará una nueva base de datos. Con esto podremos tener todas las bases de datos diferentes que queramos con una única imagen MySQL.
A continuación se muestra el manifiesto YAML que crea el ConfigMap que contiene el script SQL de inicialización de la base de datos.
ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: initsqlsource
data:
source: https://gist.githubusercontent.com/ualmtorres/eb328b653fcc5964f976b22c320dc10f/raw/448b00c44d7102d66077a393dad555585862f923/init.sqlDesplegaremos el ConfigMap con:
$ kubectl apply -f initsqlsource-configmap.yamlTambién contaremos con un objeto Secret para almacenar la contraseña del usuario root. Este sería su manifiesto YAML
apiVersion: v1
kind: Secret
metadata:
name: mysqlpassword
type: Opaque
data:
password: cGFzc3dvcmQ=Desplegaremos el Secret con:
$ kubectl apply -f credentials-secret.yamlPor último, crearemos el pod que incluye el contenedor MySQL y el Init Container que lo inicializa. El pod contiene un volumen que comparten ambos contenedores. El Init Container descarga el script SQL de inicialización en el volumen. Posteriormente, el contenedor MySQL monta ese volumen en el directorio de scripts de inicialización de forma que al arrancar por primera vez inicialice la base de datos con el script descargado por el Init Container.
Este sería el manifiesto YAML del pod que incluye el Init Container, el contenedor MySQL y el volumen compartido por los dos contenedores.
apiVersion: apps/v1
kind: Deployment
metadata:
name: initdb
spec:
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql (1)
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD (2)
valueFrom:
secretKeyRef:
name: mysqlpassword
key: password
ports:
- containerPort: 3306
volumeMounts: (3)
- name: workdir
mountPath: /docker-entrypoint-initdb.d
initContainers:
- name: install (4)
image: busybox
env:
- name: SQLSOURCE (5)
valueFrom:
configMapKeyRef:
name: initsqlsource
key: source
command: (6)
- wget
- "-O"
- "/work-dir/init.sql"
args: ["$(SQLSOURCE)"]
volumeMounts: (7)
- name: workdir
mountPath: "/work-dir"
dnsPolicy: Default
volumes: (8)
- name: workdir
emptyDir: {}| 1 | Contenedor MySQL |
| 2 | Inicialización de la variable de entorno con el Secret que contiene la contraseña del usuario root |
| 3 | Montar el volumen workdir, definido al final del script, en el directorio /docker-entrypoint-initdb.d del contenedor |
| 4 | Contenedor de inicialización |
| 5 | Inicialización de la variable de entorno con el ConfigMap que contiene la URL con el script SQL que inicializará la base de datos |
| 6 | Comando de inicialización para ejecutar al crear el Init Container |
| 7 | Montar el volumen workdir en el directorio /work-dir del InitContainer |
| 8 | Volumen que almacenará el script de inicialización de la base de datos |
|
El volumen |
Lanzamos el despliegue del Deployment:
$ kubectl apply -f initdb-deployment.yamlTras su creación, haremos un port forward al contenedor creado:
$ kubectl port-forward initdb-87b65d485-89m4c 3306:3306Por último, abrimos una sesión con un cliente MySQL (usuario: root, password: password). Dado que tenemos los puertos redirigidos, las peticiones al puerto 3306 de nuestro equipo irán al puerto 3306 del contenedor. Podremos comprobar que el contenedor tiene inicializada una base de datos, la base de datos que inicializa el script almacenado en la URL especificada en el ConfigMap.
12. Apéndice. Cheat Sheet
12.1. Comandos Minikube
-
minikube version -
minikube start -
minikube dashboard -
minikube service <nombre-servicio> -
minikube delete
12.2. Comandos kubectl
-
kubectl version -
kubectl cluster-info -
kubectl get nodes|deployments|services|pods [--show-labels] -
kubectl run <deployment> --image=<image> --port=<container-port> -
kubectl expose deployment <deployment>> --type=NodePort -
kubectl describe pods|deployments|services <resource> -
kubectl scale deployments <deployment> --replicas=<number-of-replicas> -
kubectl delete pods|deployments|services <resource> -
kubectl set image deployments <deployment> <deployment>=<image> -
kubectl rollout undo deployments <deployment> -
kubectl apply -f <filename-or-URL> -
kubectl logs <pod> -
kubectl exec <pod> <command>
12.3. Herramientas interesantes
-
kubectlykubens: Cambio de namespace contexto
cloud_provider: name: "openstack" openstackCloudProvider: block_storage: ignore-volume-az: true trust-device-path: false global: auth-url: "http://192.168.64.12:5000/v3/" domain-name: "default" tenant-name: "mtorres" username: "mtorres" password: "xxx" load_balancer: create-monitor: false manage-security-groups: false monitor-max-retries: 0 use-octavia: false metadata: request-timeout: 0
12.4. Contextos
El archivo de contextos
Disponible en ~/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority: /Users/manolo/.minikube/ca.crt
server: https://192.168.99.100:8443
name: minikube
contexts:
- context:
cluster: minikube
user: minikube
name: minikube
current-context: ""
kind: Config
preferences: {}
users:
- name: minikube
user:
client-certificate: /Users/manolo/.minikube/client.crt
client-key: /Users/manolo/.minikube/client.keyObtener los contextos
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
minikube minikube minikubeAñadir un contexto nuevo
Obtener los datos de conexión a Rancher desde

Ahí aparecen los datos de conexión al cluster. Ahí se encuentran los datos que tenemos que copiar en el archivo ~/.kube/config

Editamos el archivo el archivo ~/.kube/config y debería quedar algo así
apiVersion: v1
clusters:
- cluster:
certificate-authority: /Users/manolo/.minikube/ca.crt
server: https://192.168.99.100:8443
name: minikube
- cluster: (1)
certificate-authority-data: XXXXXXXXXXXXXXXXXXX
name: produccion-ci
contexts:
- context:
cluster: minikube
user: minikube
name: minikube
- context: (2)
cluster: produccion-ci
namespace: mtorres
user: user-XXXXXX
name: produccion-ci
current-context: ""
kind: Config
preferences: {}
users:
- name: minikube
user:
client-certificate: /Users/manolo/.minikube/client.crt
client-key: /Users/manolo/.minikube/client.key
- name: user-XXXXX (3)
user:
token: XXXXXXXXXXXXXXXXXXXXX| 1 | Datos del cluster de Rancher |
| 2 | Datos del nuevo contexto |
| 3 | Datos del usuario |
Usar un contexto
$ kubectl config use-context produccion-ci
Switched to context "produccion-ci".Si ahora consultamos los contextos, veremos que el contexto activo es produccion-ci. Por tanto, todas las operaciones que hagamos con kubectl a partir de ahora se dirigirán contra ese contexto (cluster-usuario-namespace).
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
minikube minikube minikube
* produccion-ci produccion-ci user-mzmh8 mtorres13. Apéndice. Service Mesh con Istio
Los microservicios se han convertido en algo habitual en las aplicaciones cloud actuales. Las arquitecturas de microservicios permiten realizar cambios en un servicio sin tener que volver a desplegar toda la aplicación. Esto permite que los microservicios pueden ser creados por grupos de desarrollo pequeños, creando sus propias herramientas y usando los lenguajes de programación más adecuados, lo que aumenta la productividad y velocidad del proyecto. Básicamente, los microservicios se construyen de forma independiente, se comunican entre sí y permiten el fallo de forma individual sin provocar una caída del funcionamiento de la aplicación completa.
Sin embargo, el desarrollo y la utilización de microservicios supone nuevos desafíos e implica la implementación y la gestión de la comunicación entre ellos. Esta lógica podría ser codificada en cada servicio, lo que aumenta su complejidad y dificultad, y a medida que el proyecto crece, se hace más necesario un service mesh.
Un service mesh es una capa complementaria a la aplicación y es responsable de la gestión del tráfico, políticas, certificados y seguridad de los servicios. Así, un service mesh no añade nueva funcionalidad a las aplicaciones. Simplemente, se dedica a sacar fuera de los servicios la lógica de comunicación, abstrayéndola a una capa de infraestructura. Así, con un service mesh los desarrolladores pueden centrarse en el desarrollo de la lógica de negocio y abstraerse de lo demás.
Para ofrecer esta funcionalidad, un service mesh introduce una colección de proxies de red. En un service mesh las peticiones entre los servicios se enrutan a través de estos proxies. Dichos proxies son implementados como sidecars, y se situan en el mismo pod que el servicio al que sirven (tráfico, seguridad, …). Si imaginamos esta red de sidecars en una capa aparte visualizaremos el service mesh.
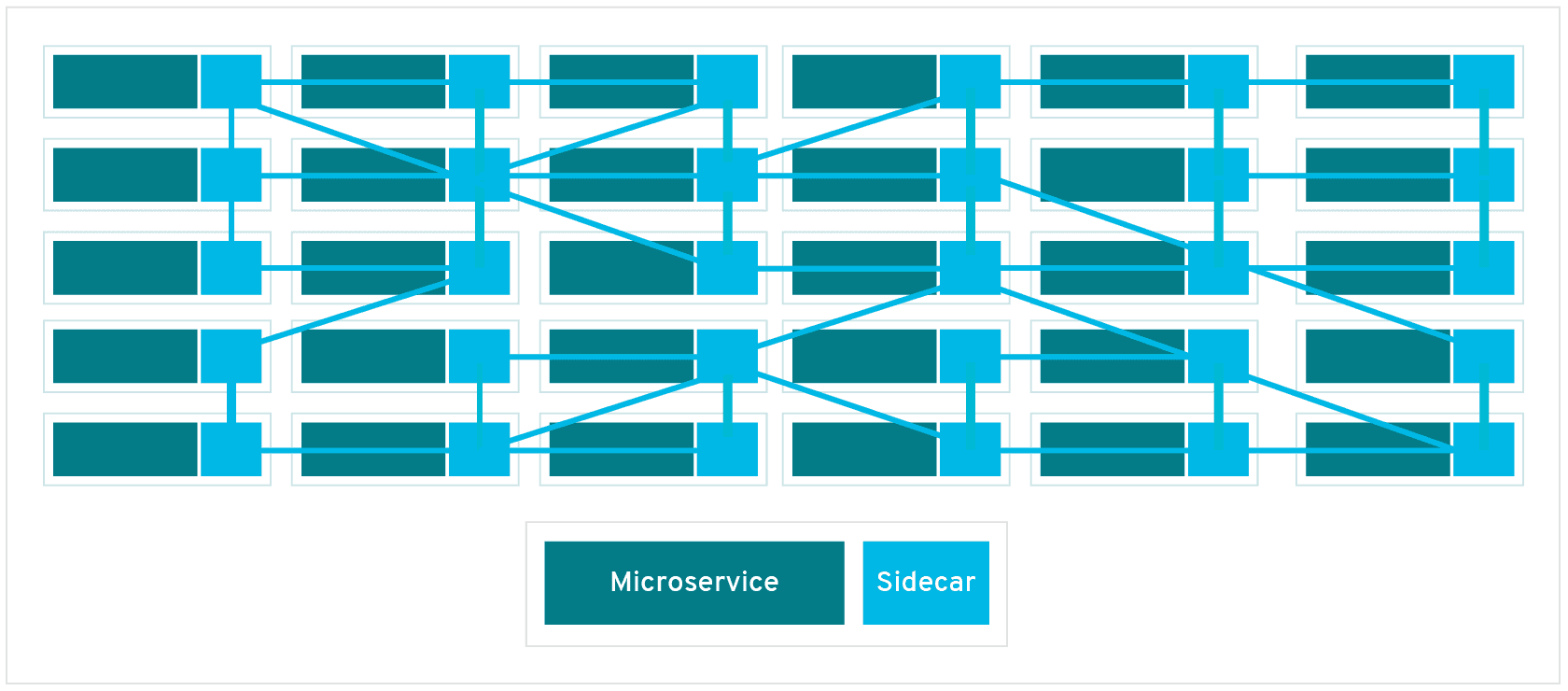
La idea entonces es inyectar un contenedor sidecar especial en el pod de cada microservicio y enrutar todo el tráfico a través de estos sidecars en lugar de a través de los propios microservicios. El controlador del service mesh interactuará con estos proxies y podrá filtrar tráfico, así como aplicar políticas de balanceo, seguridad y limitación de tráfico.
Sin un service mesh, cada microservicio debería incluir la lógica de gobierno y de comunicación con otros servicios, lo que añade una complejidad extra al desarrollo del servicio. Además, el disponer de un service mesh en entornos normalizados permite tratar de forma estándar el problema del tráfico, así como la gestión de políticas, seguridad y certificados entre servicios, independientemente de la plataforma en la que estén desplegadas nuestras aplicaciones.
En el contexto de service mesh se suelen tratar con varioss proyectos. Los más habituales son los siguientes:
-
Istio: _Service mesh que permite conectar, asegurar, controlar y observar servicios.
-
Kiali: Extiende estas características de gestión del tráfico incorporando observabilidad y visualización de servicios de la red. Kiali ofrece una forma sencilla de ver la topología de un _service mesh y observar cómo interactúan los servicios.
-
Jaeger: Se encarga del tracing y permite analizar una petición desde el principio hasta el final, y comprobar las latencias de cada una de las etapas por las que va pasando.
-
Prometheus: Sistema de monitorización y alertas que almacena en forma de series temporales la actividad del _mesh (peticiones, volumen de descarga, tiempos de resolución, errores, …)
13.1. Istio
Istio viene a incorporarse al vocabulario marinero y ballenero del ecosistema de Docker y Kubernetes. Istio es una palabra griega que significa navegar.
|
Istio está disponible en Rancher desde la versión 2.3.0-alpha5. Basta activarlo en el menú |
La figura siguiente ilustra una aplicación sin Istio. En ella, cada microservicio es el responsable de implementar la funcionalidad de discovery, balanceo, resilencia, métricas y trazado.
La figura siguiente ilustra cómo en las aplicaciones basadas en Istio los pods están formados por dos contenedores: el contenedor propio del microservicio y el del sidecar. Al sidecar se le delegan las tareas de discovery, balanceo, resilencia, métricas y trazado, lo que facilita el desarrollo de los microservicios.
Istio ofrece una forma declarativa, mediante la creación de manifiestos YAML, de gestión del tráfico, enrutado selectivo de peticiones (en lugar del round robin que ofrece Kubernetes), diferentes tipos de despliegue (canary, A/B, blue/green), resilencia a nivel de red (con opciones de retry, timeout), control de acceso, observación de microservicios distribuidos comprendiendo los flujos y trazas y pudiendo ver las métricas importantes de forma inmediata, inyección de caos para poner a prueba la resilencia de aplicaciones y servicios, por citar algunas de sus funcionalidades destacadas.
Para activar el uso de Istio en un namespace (p.e. default) se haría con
kubectl label namespace default istio-injection=enabled13.2. Arquitectura de Istio
Istio consta de un plano de control y un plano de datos. El plano de datos está formado por proxies que se integran en los pods de la aplicación. Usando el patrón del sidecar, cada instancia de la aplicación tendrá su proxy dedicado a través del cual pasa todo el tráfico antes de llegar a la aplicación. Estos proxies individuales son gestionados individualmente por Istio para enrutar, filtrar y aumentar el tráfico según sea necesario.
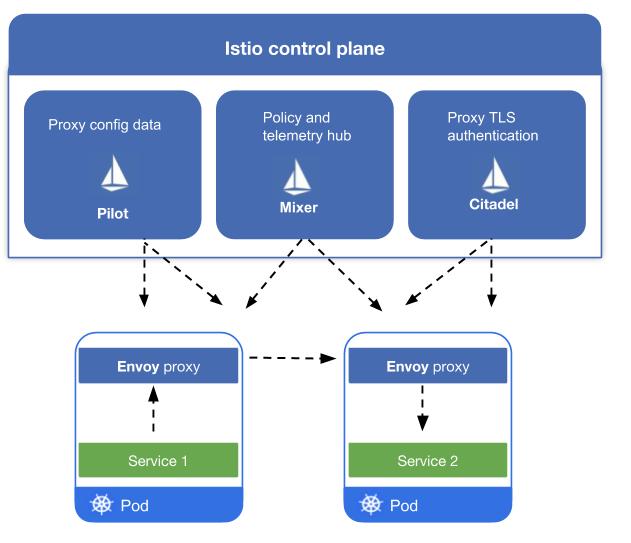
Además, Istio permite realizar deciciones de enrutado en función de las cabeceras HTTP (p.e. tipo de navegador, usuario, …)
|
Algo a tener en cuenta es que los componentes del plano de control son aplicaciones sin estado, lo que favorece que puedan escalar horizontalmente. Todos los datos están almacenados en etcd como descricpciones personalizadas de recursos Kubernetes. |
Sin embargo, toda esta funcionalidad tiene un coste sobre la infraestructura. Cuando mayor sea el cluster, mayor será la carga añadida al sistema. Cada sidecar consume bastante RAM (unos 350Mb). Además, añade una latencia de unos 10 ms a cada petición.
13.3. Control de tráfico y técnicas de despliegue
-
Despliegue canary: Se despliega en producción una nueva versión del código, pero sólo se dirige a ella una parte del tráfico. A la nueva versión quizá sólo tengan acceso clientes de prueba, empleados, usuarios de iOS, etcétera. Una vez desplegado el canario, éste se monitoriza para comprobar la posible existencia de excepciones, comportamiento no satisfactorio, bajada del rendimiento, y demás. Si el canario no muestra indicios de que presente problemas, se puede ir aumentando paulatinamente el tráfico hacia él. En cambio, si presenta un comportamiento inaceptable, se puede retirar fácilmente de producción.
-
Control del tráfico: Se pueden especificar reglas de enrutado que controlen el tráfico a un conjunto de pods. En concreto, Istio usa los recursos
DestinationRuleyVirtualServiceen forma de manifiestos YAML para describir estas reglas.-
DestinationRule: Define grupos (subsets) de pods. Normalmente definiremos un subset para cada servicio y el subset estará formado por cada una de las versiones que se pueden utilizar del servicio. A continuación se muestra un fragmento YAML con la definición de unaDestinationRuleque define dos versiones posibles a las que enrutar tráfico con Istio.apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: jsonproducer spec: host: jsonproducer subsets: - name: v0 labels: version: v0 - name: v1 labels: version: v1 -
VirtualServicedirige el tráfico a un subset, y lo puede hacer basándose en porcentajes, cabeceras, direcciones IP, por citar algunas. La selección de pods afectados es similar al modelo de selectores utilizado por Kubernetes para selección basada en etiquetas (labels). A continuación se muestra un fragmento YAML con la definición de unVirtualServicepara aplicar un enrutado del 80% de las peticiones a la versiónv0de un microservicio y el 20% a la versiónv1.apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: jsonproducer spec: hosts: - jsonproducer http: - route: - destination: host: jsonproducer subset: v0 weight: 80 - destination: host: jsonproducer subset: v1 weight: 20
Este comportamiento del enrutado no es sólo para el tráfico de entrada externo. Es para toda la comunicación inter-servicio en el service mesh. Así, si hubiese servicios desplegados en Kubernetes, pero que no sean parte del mesh, dichos servicios no estarían afectados por estas reglas y se regirían por las reglas de balanceo de Kubernetes (round-robin).
-
-
Dark launch: Se trata de un despliegue a producción que no es visible a los clientes. En este caso Istio permite duplicar (mirror) el tráfico a una versión de la aplicación y ver cómo se comporta respecto a la versión del pod en producción. De esta forma se están realizando peticiones en las condiciones de producción al nuevo servicio sin afectar al tráfico de la versión en producción. No obstante, hay que tener una consideración especial con los servicios que traten con datos o estén vinculados a otros servicios, para no introducir duplicados, provocar inconsistencias y otros problemas derivados de la duplicación de peticiones.
13.4. Técnicas de resilencia
-
Circuit breaker: Determina el número máximo de peticiones que puede soportar un pod. Pasado ese valor no admite más hasta que se recupere.
-
Pool ejection: Saca de un nodo a un pod que esté dando fallos creando un nuevo pod que los sustituya en otro nodo.
-
Retries: Reenvía la petición a otro pod al encontrar un caso de circuit breaker o pool rejection.
13.5. Caso práctico
Para no perdernos en los detalles usaremos un ejemplo muy sencillo con dos servicios: uno que produce datos y otro que los presenta. Podríamos ver este ejemplo como un ejemplo muy reducido de backend y frontend.
El servicio que genera datos se denomina jsonproducer y genera un documento JSON con un único elemento nombre y un valor asociado (p.e. {"nombre": "manolo"}). De este servicio se cuenta con dos versiones, cada una con su imagen Docker correspondiente. La primera versión (v0) devuelve el elemento JSON {"nombre": "manolo"}. La segunda versión (v1) devuelve el elemento JSON {"nombre": "Manuel Torres"}
El servicio que consume datos se denomina jsonreader y usará los datos leídos de jsonproducer para presentarlos al usuario en forma de saludo, mostrando Hola seguido del nombre leído del JSON devuelto por la versión de jsonproducer usada (Hola manolo cuando use v0 y Hola Manuel Torres cuando use v1).
13.5.1. Creación de todos los servicios
En primer lugar vamos a desplegar en el cluster de Kubernetes todos los recursos (Service y Deployment) con todas sus versiones correspondientes. Posteriormente, con Istio controlaremos el tráfico que se dirige a cada versión desplegada. En nuestro ejemplo se definirán dos objetos Deployment, uno para cada una de las versiones del jsonproducer (v0 y v1) que quedarán desplegadas en el cluster.
Cada despliegue incorpora en los metadatos el nombre que le queremos dar, así como unas etiquetas con su versión, que le permitirán ser seleccionado posteriormente cuando se definan los servicios virtuales. Además, en la spec del despliegue se usarán etiquetas en matchLabels que permitirán más adelante a Istio distinguir los pods correspondientes a cada despliegue.
En este ejemplo usaremos dos versiones (dos recursos Deployment) del jsonproducer. La primera está basada en la imagen ualmtorres/jsonproducer:v0 que devuelve {"nombre": "manolo"}. La segunda está basada en la imagen ualmtorres/jsonproducer:v1 que devuelve {"nombre": "Manuel Torres"}. Con este ejemplo tan sencillo nos bastará para ver a Istio en acción controlando el tráfico.
El manifiesto siguiente (greeter.yaml) configura varios recursos Kubernetes:
-
Dos servicios (
jsonproduceryjsonreader). -
Dos
Deploymentdejsonproducer, correspondientes a las dos versiones (jsonproducer-v0yjsonproducer-v1). -
Deploymentdejsonreader(jsonreader-v0).
#########################################################
# jsonproducer service
#########################################################
apiVersion: v1
kind: Service
metadata:
name: jsonproducer
labels:
app: jsonproducer
service: jsonproducer
spec:
ports:
- port: 80
name: http
selector:
app: jsonproducer
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: jsonproducer-v0 (1)
labels:
app: jsonproducer
version: v0
spec:
replicas: 1
selector:
matchLabels:
app: jsonproducer
version: v0 (2)
template:
metadata:
labels:
app: jsonproducer
version: v0
spec:
containers:
- name: jsonproducer
image: ualmtorres/jsonproducer:v0 (3)
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: jsonproducer-v1 (4)
labels:
app: jsonproducer
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: jsonproducer
version: v1 (5)
template:
metadata:
labels:
app: jsonproducer
version: v1
spec:
containers:
- name: jsonproducer
image: ualmtorres/jsonproducer:v1 (6)
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
###########################################################
# jsonreader services
###########################################################
apiVersion: v1
kind: Service
metadata:
name: jsonreader
labels:
app: jsonreader
service: jsonreader
spec:
ports:
- port: 80
name: http
selector:
app: jsonreader
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: jsonreader-v0
labels:
app: jsonreader
version: v0
spec:
replicas: 1
selector:
matchLabels:
app: jsonreader
version: v0
template:
metadata:
labels:
app: jsonreader
version: v0
spec:
containers:
- name: jsonreader
image: ualmtorres/jsonreader:v0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---| 1 | Versión v0 del servicio |
| 2 | Selector para determinar los pods asociados a la versión v0 del servicio |
| 3 | Imagen v0 del servicio |
| 4 | Versión v1 del servicio |
| 5 | Selector para determinar los pods asociados a la versión v1 del servicio |
| 6 | Imagen v1 del servicio |
Lo aplicaremos en nuestro cluster con
$ kubectl apply -f https://gist.githubusercontent.com/ualmtorres/b651f3c73aa87376752c606e3747b151/raw/9f289b6500b75d93f22b4b36c63c6e3f409f1ccf/greeter.yamlDespués, podemos consultar los servicios y deployments configurados
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
jsonproducer ClusterIP 10.43.88.162 <none> 80/TCP 40s
jsonreader ClusterIP 10.43.106.61 <none> 80/TCP 40s
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
jsonproducer-v0 1/1 1 1 40s
jsonproducer-v1 1/1 1 1 40s
jsonreader-v0 1/1 1 1 40s|
De cara a poder probar los distintos escenarios que vamos a desarrollar, sería conveniente crear el Ingress en Rancher para los servicios |
13.5.2. Creación de los subsets mediante DestinationRule
A continación vamos a definir todas las versiones de un servicio que vamos a tener elegibles en el cluster de Kubernetes y que posteriormente serán seleccionadas o usadas cuando pasemos a controlar el tráfico a cada versión. Las DestinationRule se usan para definir las distintas instancias o versiones disponibles que se pueden usar de cada servicio. Cada servicio tendrá su DestinationRule con lo siguiente:
-
metatada.name: Nombre. -
spec.host: Host contra el que se lanzará este servicio. Puede ser un nombre DNS (admite wildcards) o un nombre de servicio válido en nuestra aplicación. -
spec.subsets: Lista de versiones de servicios a configurar. Cada versión tendrá su nombre (name) y usará una etiqueta (p.e.labels.version: v0) para emparejarse con los pods de su versión de acuerdo a lo definido en el selectormatchLabelsdel objetoDeploymentdel manifiesto del apartado anterior.
El manifiesto siguiente (destination-rule-all.yaml) corresponde a los dos recursos DestinationRule que vamos a crear, uno para cada servicio, jsonproducer y jsonreader, respectivamente. Cada DestinationRule incluye los _subsets o versiones de recursos Deployment de cada servicio. En este caso, indicamos que jsonreader consta sólo de un subset al que llegaremos a través de la versión v0 del servicio (host) jsonreader. En cambio, jsonproducer consta de dos subset , a los que llegaremos a través de las versiones v0 o v1 del servicio (host) jsonproducer.
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: jsonreader
spec:
host: jsonreader
subsets:
- name: v0
labels:
version: v0
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: jsonproducer
spec:
host: jsonproducer (1)
subsets:
- name: v0
labels:
version: v0
- name: v1 (2)
labels:
version: v1 (3)
---| 1 | Nombre que le damos a nuestro host y que luego será usado por los servicios virtuales para dirigir el tráfico a una versión concreta de las definidas en los subsets. Este nombre debe coincidir con los nombres de servicio usados en el código de la aplicación |
| 2 | Nombre dado a esta versión del servicio |
| 3 | Etiqueta usada para seleccionar los pods a los que corresponde esta versión. Se emparejarán los pods que tengan version: v1 en su MatchingLabels |
Lo aplicaremos en nuestro cluster con
$ kubectl apply -f https://gist.githubusercontent.com/ualmtorres/440e04403d2ec662bda2a9cc29721a75/raw/37542b7886916efe9f306c6d9c48bafef91b335d/destination-rule-all.yamlDespués, podemos consultar las DestinationRule configuradas
$ kubectl get destinationrules
NAME HOST AGE
jsonproducer jsonproducer 40s
jsonreader jsonreader 40s13.5.3. Creación de los servicios virtuales para el control del tráfico a versiones específicas
Por último, crearemos los VirtualService para indicarle a Istio la versión concreta de cada microservicio desplegado a la que queremos desviar el tráfico. Este recurso es el que Istio usará para configurar los proxies que controlarán el tráfico en el mesh.
Con los servicios virtuales conseguimos poner en marcha la capa complementaria a la aplicación que controlará su tráfico. Esto nos permite usar y cambiar a versiones concretas, derivar un porcentaje del tráfico a versiones determinadas (p.e. para despliegues canary), tener versiones diferentes para usuarios diferentes, control de tráfico basado en CIDR, y demás.
|
Con Istio podremos cambiar el enrutado a unos servicios u otros de forma dinánica. Basta con aplicar otro manifiesto con los nuevos valores de enrutado de los |
El manifiesto siguiente (all-v0.yaml) define un servicio virtual para cada servicio de nuestra aplicación. En este ejemplo cada servicio virtual usa la versión v0 de los Deployment desplegados en el cluster.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: jsonreader
spec:
hosts:
- jsonreader
http:
- route:
- destination:
host: jsonreader
subset: v0
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: jsonproducer
spec:
hosts:
- jsonproducer (1)
http:
- route:
- destination:
host: jsonproducer (2)
subset: v0 (3)
---| 1 | Nombre DNS (admite prefijos wildcard) o nombres de servicios del mesh |
| 2 | Servicio al que se quiere dirigir el tráfico |
| 3 | Versión a la que se quiere dirigir el tráfico |
Lo aplicaremos en nuestro cluster con
$ kubectl apply -f https://gist.githubusercontent.com/ualmtorres/e900fc85856fec3d918575e6e3d91d29/raw/35d799ca518f8e5ad76112ecf575a6b8e62f3ff3/all-v0.yamlDespués, podemos consultar los servicios virtuales configurados
$ kubectl get virtualservices
NAME GATEWAYS HOSTS AGE
jsonproducer [jsonproducer] 40s
jsonreader [jsonreader] 40sSi lanzamos ahora peticiones contra jsonreader o contra jsonproducer siempre se selecciona la versión v0 de cada una de ellos (jsonproducer siempre devuelve {"nombre":"manolo"}
13.5.4. Desvío de una fracción del tráfico a una nueva versión
Como comentamos en el apartado Control de tráfico y técnicas de despliegue, en los despliegues canary se despliega una nueva versión del código, pero sólo se dirige a ella una parte del tráfico con la intención de comenzar a probar el funcionamiento de una nueva versión. Con Istio, este tipo de despliegue lo realizaremos aplicando un nuevo servicio virtual que desviará el 80% del tráfico a la versión v0 de jsonproducer y el 20% del tráfico a la versión v1 de jsonproducer.
El manifiesto siguiente (virtual-service-jsonproducer-20-v1.yaml) define un servicio virtual para cada servicio de nuestra aplicación y modifica el original de jsonproducer para desviar el 80% del tráfico a v0 y el 20% a v1.
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: jsonreader
spec:
hosts:
- jsonreader
http:
- route:
- destination:
host: jsonreader
subset: v0
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: jsonproducer
spec:
hosts:
- jsonproducer
http:
- route:
- destination: (1)
host: jsonproducer
subset: v0
weight: 80 (2)
- destination: (3)
host: jsonproducer
subset: v1
weight: 20 (4)
---| 1 | Configuración de la versión v0 de jsonproducer como destino de tráfico del servicio virtual |
| 2 | Porcentaje de tráfico que se dirigirá a la versión v0 (80%) |
| 3 | Configuración de la versión v1 de jsonproducer como destino de tráfico del servicio virtual |
| 4 | Porcentaje de tráfico que se dirigirá a la versión v1 (20%) |
Lo aplicaremos en nuestro cluster con
$ kubectl apply -f https://gist.githubusercontent.com/ualmtorres/7c04cf736f2283fa3c2ffb6bc81a8c30/raw/ae7eb38d0c1d66d08f6792021da15b5ac5462507/virtual-service-jsonproducer-20-v1.yamlSi lanzamos ahora un gran número de peticiones contra jsonreader veremos como estadísticamente se tiene a que el 80% de las peticiones muestren los datos de la v0 de jsonproducer y el 20% muestre los datos de la v1 de jsonproducer.
Experimento:
$ ab -n 100 http://greeter-jsonreader.default.192.168.65.94.xip.io/
This is ApacheBench, Version 2.3 <$Revision: 1663405 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking greeter-jsonreader.default.192.168.65.94.xip.io (be patient).....done
Server Software: nginx/1.15.6
Server Hostname: greeter-jsonreader.default.192.168.65.94.xip.io
Server Port: 80
Document Path: /
Document Length: 11 bytes
Concurrency Level: 1
Time taken for tests: 13.647 seconds
Complete requests: 100
Failed requests: 0
Total transferred: 29965 bytes
HTML transferred: 1100 bytes
Requests per second: 7.33 [#/sec] (mean)
Time per request: 136.466 [ms] (mean)
Time per request: 136.466 [ms] (mean, across all concurrent requests)
Transfer rate: 2.14 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 46 49 4.6 47 73
Processing: 55 88 37.7 77 268
Waiting: 55 85 37.0 72 268
Total: 101 136 37.5 126 315
Percentage of the requests served within a certain time (ms)
50% 126
66% 137
75% 145
80% 151
90% 196
95% 208
98% 258
99% 315
100% 315 (longest request)Grafo de tráfico en Rancher
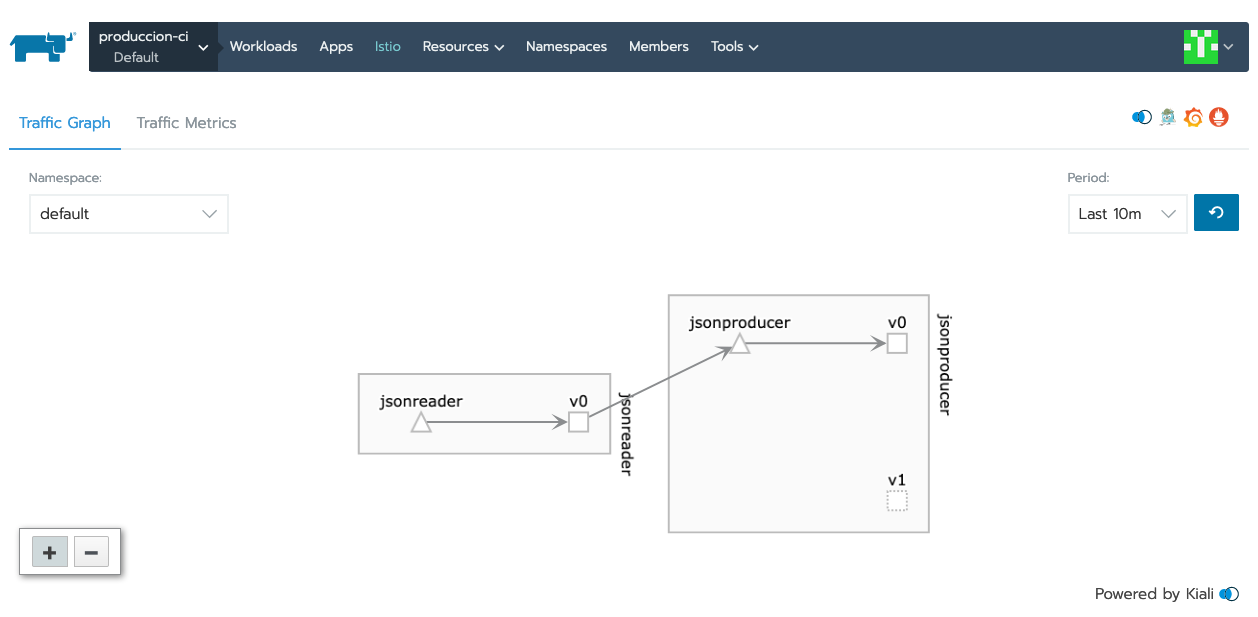
Métricas de acceso en Rancher
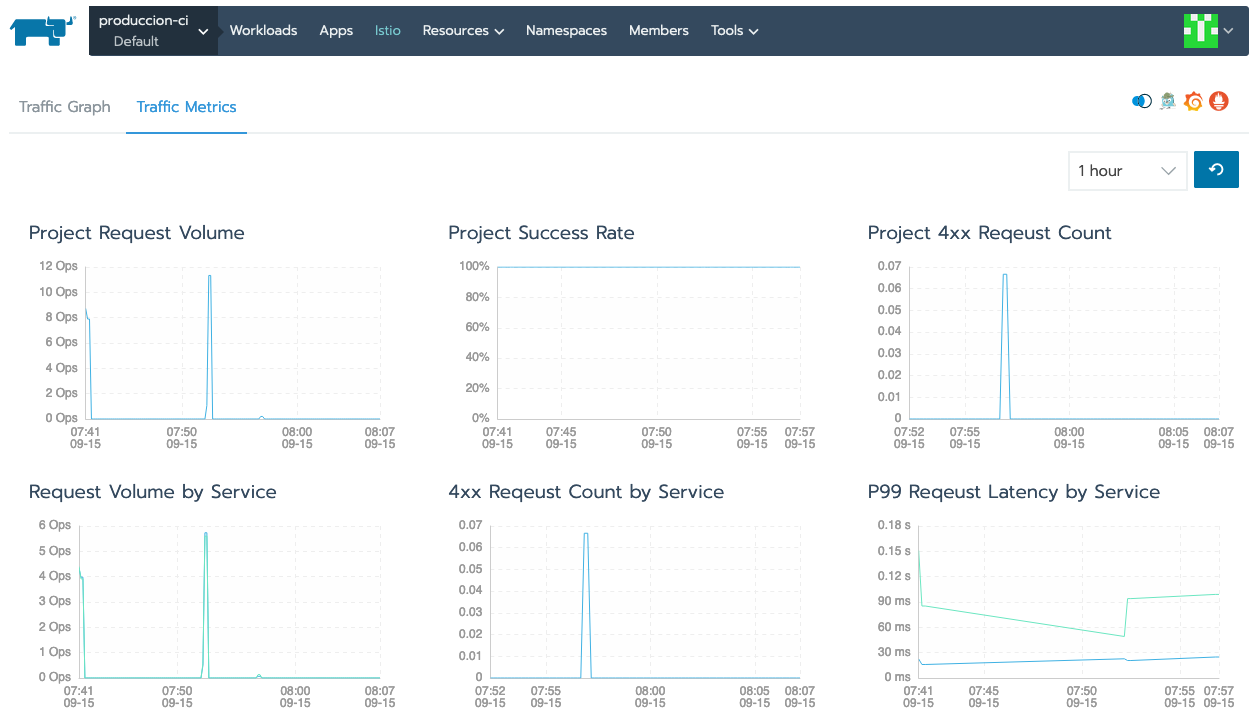
Actividad de los servicios en Kiali
Visión general de las trazas con Jaeger
Detalles de una traza con Jaeger
Actividad del servicio con Grafana
Consultas de métricas en Prometheus
14. Referencias
-
Kubernetes under the hood. Marcos Vallim.
-
Getting Started with Kubernetes. The IT Hollow.
-
Kubernetes: part 1 — architecture and main components overview. Arseny Zinchenko.
-
Kubernetes Services simply visually explained. Kim Wuestkamp.
-
Using environment files over injected environment variables in Kubernetes. Matt Glaman.
-
Almacenamiento en Kubernetes. PersistentVolumen. PersistentVolumenClaims. José Domingo Muñoz.
-
Learn about the basics of Kubernetes Persistence (Part 1). Abhishek Gupta.
-
Tutorial: Basics of Kubernetes Volumes (Part 2). Abhishek Gupta.
-
4 command-line tools for Kubernetes: Linux edition. Don Schenck.