Resumen
En este tutorial se introduce Oracle Data Integrator (ODI), la solución de Oracle para la construcción, despliegue y administración de almacenes de datos y para entornos de Business Intelligence. Se describe la arquitectura y principales componentes de ODI y se describe de forma concisa los pasos para la creación del repositorio ODI, la importación de archivos de texto y la creación de dimensiones y cubos.
-
Conocer la arquitectura de ODI.
-
Aprender a crear un repositorio Master y repositorios de trabajo.
-
Aprender a importar archivos de texto mediante ODI.
-
Aprender a crear dimensiones y cubos mediante ODI.
|
Este tutorial está basado en la documentación oficial de Oracle Data Integrator disponible en https://docs.oracle.com/middleware/12212/odi/index.html |
1. Introducción a Oracle Data Integrator (ODI)
ODI ofrece una solución unificada para la construcción, despliegue y administración de almacenes de datos y para entornos de Business Intelligence. Además, combina todos los elementos de la integración de datos (movimiento, sincronización, calidad, administración y servicios de datos) para asegurar que la información esté disponible de forma precisa y consistente en sistemas complejos.
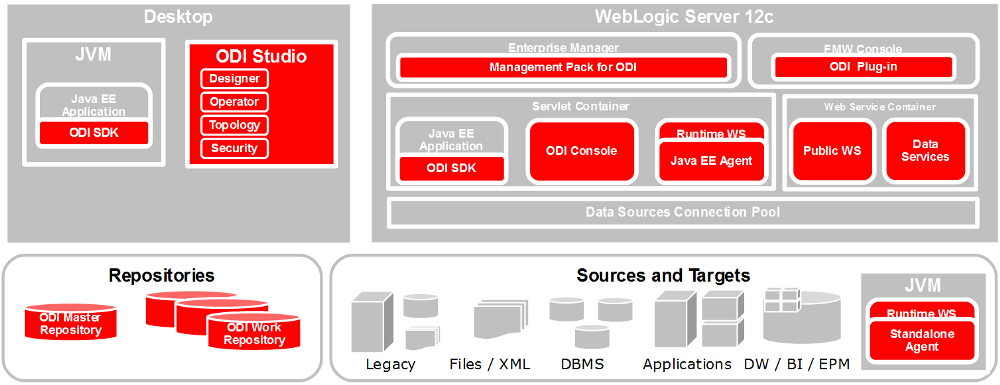
El componente principal de la arquitectura ODI es el repositorio. El repositorio de ODI almacena información de configuración relacionada con metadatos de la aplicación, proyectos, escenarios y logs de ejecución. Es posible contar con varias instancias del repositorio, lo que permite tener entornos separados. Además, el repositorio actúa como un sistema de control de versiones a través de un número de versión para los objetos creados. El repositorio de ODI lo instalaremos en una base de datos Oracle.
1.1. El repositorio Máster y los repositorios de trabajo
El repositorio ODI está formado por un repositorio Master y varios repositorios de trabajo.
El repositorio Master almacena:
-
Información de seguridad, como usuarios, perfiles y privilegios.
-
Información sobre tecnologías, servidores, esquemas e idiomas.
-
Objetos versionados y archivados.
Los repositorios de trabajo almacenan:
-
Modelos, que incluyen la definición de esquemas, datastores, definiciones de campos y atributos, restricciones de calidad de datos, y demás.
-
Proyectos, que incluyen reglas de negocio, paquetes, procedimientos, módulos de conocimiento (funcionalidad), y demás.
-
Resultados sobre la ejecución de escenarios.
1.2. Los navegadores de ODI
Las operaciones que realizamos con ODI las hacemos a través de cuatro navegadores: Topology, Designer, Operator y Security.
-
En Topology definiremos la arquitectura física y lógica indicando las tecnologías que usan las fuentes y destinos de los datos que vamos a usar (p.e. archivos de texto, bases de datos Oracle, otras bases de datos relacionales (MySQL, PostgreSQL, SQL Server, …), bases de datos NoSQL (MongoDB, Cassandra, …) y el ecosistema Hadoop (HDFS, HBase, Hive, Pig, Spark, …)
-
En Designer crearemos los proyectos (que incluirán los mappings y los paquetes para ejecutar los mappings) y configuraremos los modelos (fuentes de datos y destinos de datos) y los cubos y dimensiones de destino.
-
En Operator podemos ver el resultado de la ejecución de los mappings y paquetes.
-
En Security gestionamos la información de seguridad de ODI relacionada con usuarios, perfiles y privilegios de los usuarios.
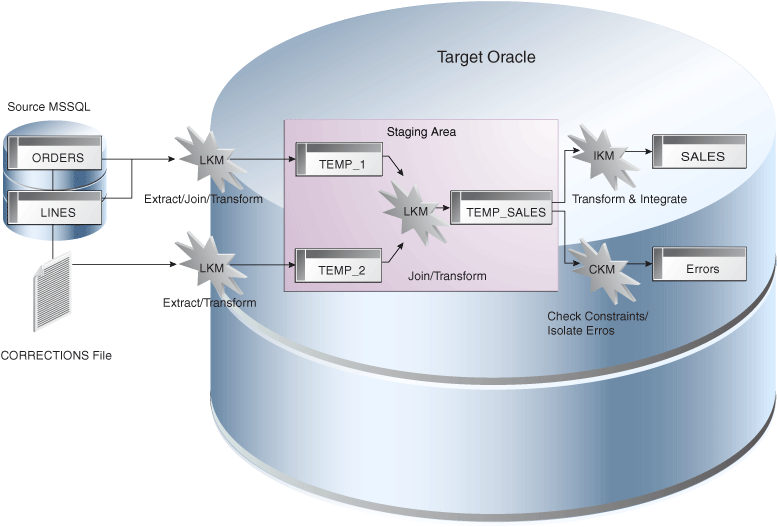
|
Las pruebas para llevar a cabo este tutorial las realizaremos con la máquina virtual configurada que ofrece Oracle para ODI 12c. En el documento de instalación y uso de la máquina virtual se encuentran los detalles sobre la configuración y puesta en marcha de la máquina virtual, así como las contraseñas de todos los usuarios. Las contraseñas básicas que usaremos serán |
2. Creación de los esquemas de usuario para el repositorio Master y los repositorios de trabajo
La base para el uso de ODI para la construcción de almacenes de datos es el repositorio ODI. Aquí veremos cómo crear el repositorio Máster y los repositorios de trabajo. Dichos repositorios se instalan en una base de datos Oracle. Para este tutorial crearemos dos esquemas Oracle, uno para el repositorio Master (granadam, Granada Master) y otro para los repositorios de trabajo (granadaw, Granada Worker).
Para crear los esquemas de usuario, desde SQL Developer ejecutaremos como usuario system los comandos siguientes:
CREATE USER granadam IDENTIFIED BY granada (1)
DEFAULT TABLESPACE users TEMPORARY TABLESPACE temp;
GRANT CONNECT, RESOURCE TO granadam;
CREATE USER granadaw IDENTIFIED BY granada (2)
DEFAULT TABLESPACE users TEMPORARY TABLESPACE temp;
GRANT CONNECT, RESOURCE TO granadaw;| 1 | El usuario granadam hace referencia al usuario granada Master. |
| 2 | El usuario granadaw hace referencia al usuario granada Worker. |
2.1. Creación del repositorio Master
En ODI, seleccionamos File - New. Aparecerá un cuadro de diálogo en el que seleccionaremos Create a New Master Repository.
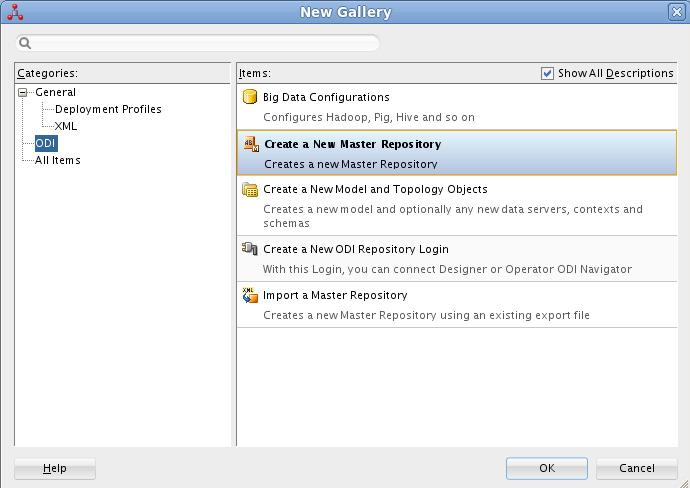
En el cuadro de diálogo introducimos los valores siguientes:
| Parámetro | Valor |
|---|---|
JDBC URL |
|
User |
granadam |
Password |
granada |
DBA User |
system |
DBA Password |
oracle |
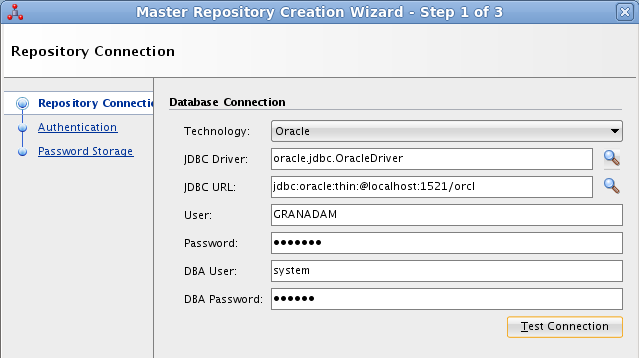
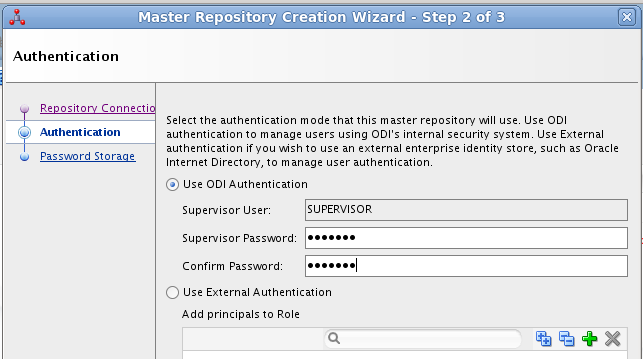
En el paso siguiente del asistente tenemos que introducir los valores de conexión que queremos usar para el usuario SUPERVISOR.
| Parámetro | Valor |
|---|---|
Supervisor Password |
granada |
Confirm Password |
granada |
2.2. Conexión al repositorio Master
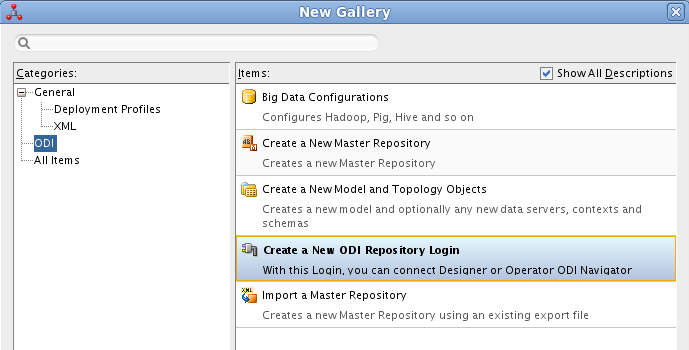
En ODI, seleccionamos File - New. Aparecerá un cuadro de diálogo en el que seleccionaremos Create a New ODI Repository Login.
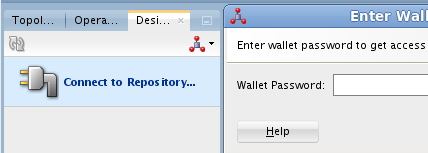
Aparecerá un cuadro de diálogo pidiéndonos la contraseña de wallet para tener acceso a nuestras credenciales. En la máquina virtual proporcionada por Oracle el password es welcome1.
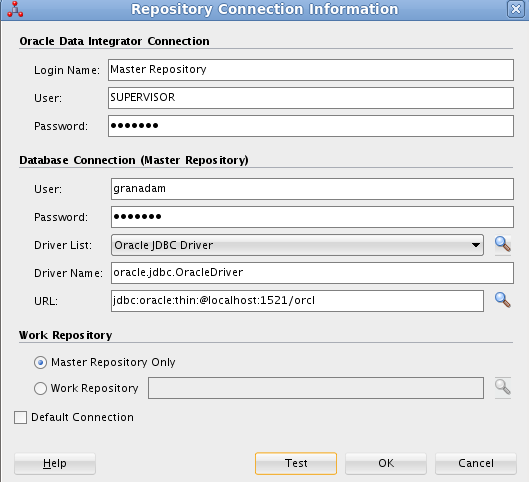
welcome1| Parámetro | Valor |
|---|---|
Login name |
Master Repository |
User |
SUPERVISOR |
Password |
granada |
User |
granadam |
Password |
granada |
Driver List |
Oracle JDBC Driver |
Driver Name |
oracle.jdbc.OracleDriver |
URL |
|
2.3. Creación del repositorio de trabajo
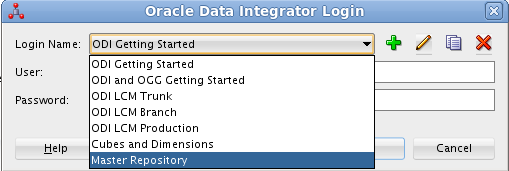
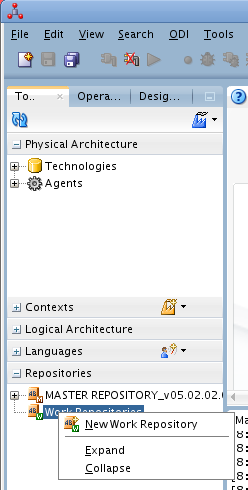
Aparecerá el cuadro de diálogo de creación del repositorio de trabajo con los valores recuperados de la conexión creada anteriormente.
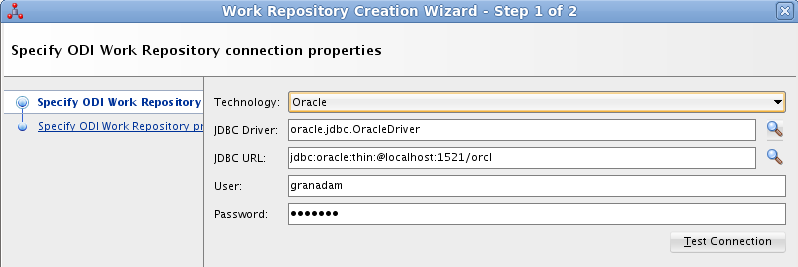
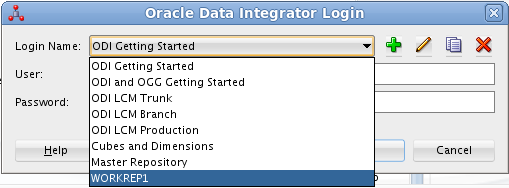
En el paso siguiente especificaremos el nombre que le queremos dar al repositorio de trabajo y el password de acceso. El nombre del repositorio de trabajo será WORKREP1 y el password será granada.
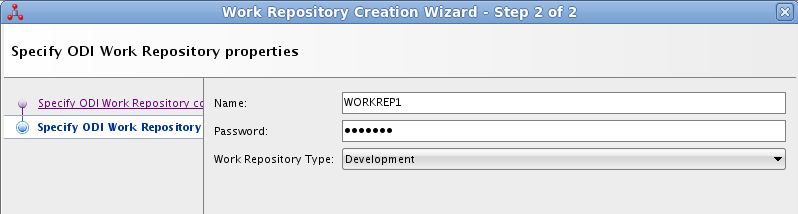
Aparecerá un cuadro de diálogo para que indiquemos si queremos crear un login al repositorio de trabajo. Indicaremos que sí e introduciremos WORKREP1, que es el nombre que dimos anteriormente al repositorio de trabajo.
Una vez creado el repositorio de trabajo, nos desconectaremos del repositorio creado seleccionando ODI - Disconnect Master Repository.
A continuación, nos conectaremos al repositorio de trabajo con el login WORKREP1, el usuario SUPERVISOR y la contraseña granada.
3. Importación de archivos de texto
Para importar archivos de texto utilizaremos un ejemplo reducido de Ventas con las dimensiones Cuando, Donde y Que.
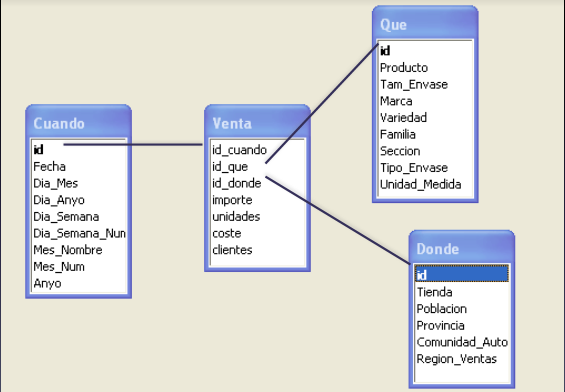
En el Anexo 1 se muestra el código SQL para la creación de las tablas.
3.1. Pasos para la importación de archivos de texto en ODI
Para poder lleva a cabo las tareas de Extracción, Transformación y Carga (ETL) de datos en ODI primero tenemos que crear la infraestructura relacionada con las fuentes y destinos ETL.
Una vez creada la infraestructura, basta con añadir las fuentes de datos, destinos de datos y configurar las operaciones de transformación y carga de datos.
3.1.1. Creación de la infraestructura ODI para la importación de datos
Antes de llevar a cabo las operaciones ETL tenemos que realizar estos pasos:
-
Definir la arquitectura física de origen (ruta en la que están almacenados los archivos de texto, p.e.
/home/oracle/Documents/data). -
Definir la arquitectura lógica de datos (nombre que usaremos para referirnos a la ruta en la que están los archivos a importar p.e.
MyFlatFiles). -
Crear las tablas de destino (p.e.
Cuando, Donde, Que, Venta). -
Definir la arquitectura física de destino (esquema Oracle en el que se almacenará el resultado del proceso ETL, p.e.
granadam). -
Definir la arquitectura lógica de destino (nombre que usaremos para referirnos al esquema Oracle donde se guardarán el resultado del ETL, p.e.
DBVentas.)
Veamos los pasos:
-
Definir la arquitectura física de origen. En este paso definimos la ruta en la que se almacenan los archivos de texto que vamos a importar.
-
Topology → Physical Architecture → Technologies → File. Clic derecho sobre
FILE_GENERICy elegir Open. -
Host:
localhost, User:oracle, Password:oracle. -
Probar conexión
-
Topology → Physical Architecture → Technologies → FILE_GENERIC. Clic derecho y elegir New Physical Schema
-
Directory (Schema) y Directory (Work Schema):
/home/oracle/Documents/data
-
-
Definir la arquitectura lógica de origen. En este paso asignamos un nombre a la ruta en la que se almacenan los archivos de texto a importar.
-
Topology → Logical Architecture → Technologies → File. Clic derecho y elegir New Logical Schema
-
Name:
MyFlatFiles, Physical Schemas listbox:FILE_GENERIC … /UGR2018/data.
-
-
Crear una carpeta donde guardar los modelos de las fuentes.
-
Designer → Models → New Model Folder.
-
Name:
FlatFilesVentas -
Designer → Models → FlatFilesVentas. Clic derecho y seleccionar New Model.
-
Name:
FFVentas, Technology:File, Logical Schema:MyFlatFiles.
-
-
Crear las tablas de destino.
CREATE TABLE …. -
Definir la arquitectura física de destino. En este paso especificamos la instancia de Oracle en la que se almacenará la importación de los datos.
-
Topology → Physical Architecture → Oracle. Clic derecho y seleccionar New Data Server
-
Name:
DBVentas, Instance:orcl, User:granadam, Password:granada. -
JDBC Driver: oracle.jdbc.OracleDriver, JDBC Url:
jdbc:oracle:thin:@localhost:1521/orcl -
Probar conexión
-
Topology → Physical Architecture → Oracle → DBVentas → New Physical Schema
-
Schema (Schema), Schema (Work Schema):
granadam
-
-
Definir la arquitectura lógica de destino. En este paso asignamos un nombre al esquema en el que estará la tabla de destino de la importación.
-
Topology → Logical Architecture → Oracle. Clic derecho y elegir New Logical Schema
-
Name:
DBVentas, Physical schema listbox:DBVentas.granadam.
-
-
Definir el modelo del destino. En este paso se crea un grupo en ODI que representa el esquema Oracle en el que estarán las tablas de destino.
-
Designer → Models → New Model.
-
Name:
DBVentas, Technology:Oracle, Logical schema:DBVentas. -
Reverse Engineer → Reverse Engineer.
-
Designer → Models → DBVentas. Seleccionar una tabla, hacer clic derecho sobre View Data. Por ahora, no hay nada.
-
-
Importación de módulos. En este paso se importan los módulos (plugins) necesarios para la importación y definir los mappings.
-
Designer → Projects → New Project
-
Name: Ventas
-
Import Knowledge modules
-
Designer → Projects → Ventas → Knowledge modules. Clic derecho y seleccionar Import knowledge modules.
-
File Import Directory. Buscar
-
File Name:
/u01/Middleware/ODI12c/odi/sdk/xml-reference -
Seleccionar IKM SQL Incremental Update y LKM File to SQL.
-
-
3.2. Importación de los archivos de texto
Una vez creada la infraestructura para el proceso ETL procederemos a la importación de los archivos de texto del ejemplo. Estos pasos se repetirán para cada uno de los archivos de texto que se vayan a importar.
-
Crear el data store asociado al archivo de texto. Para ello, se obtendrá la estructura del archivo de texto a importar.
-
Designer → Models → FlatFilesVentas → FFVentas. Clic derecho y seleccionar New Datastore
-
Elegir nombre para el archivo, seleccionar el archivo de texto, marcar si es delimitado, indicar si hay fila de encabezado, indicar si los separadores de registro y de campo son MS-DOS o Unix, obtener una vista previa de los datos.
-
-
Preparar el mapping.
-
Designer → Projects → Ventas → First Folder → Mappings. Clic derecho y seleccionar New Mapping
-
Name: p.e.
MappingCuando -
Colocar archivo de origen y tabla de destino y crear mapping de los atributos.
-
Seleccionar tabla de destino. Logical tab → Target. Integration Type:
Incremental Update -
Abrir ventana Properties. Physical tab. Seleccionar el proceso Loading KM. Loading Knowledge Module:
LKM SQL to Oracle.
-
-
Validar y ejecutar el mapping
-
En Operations → Session List → Sessions se puede ver el estado de la ejecución del mapping.
Las tablas siguientes muestran la estructura de los archivos de texto. Em importante seguir estas indicaciones a la hora de especificar el tipo de las columnas importadas para que luego no haya errores de falta de corrspondencia de tipos al ejecutar los mappings.
| Columna | Tipo de datos |
|---|---|
id |
NUMBER |
diaMes |
NUMBER |
diaSemana |
VARCHAR2(20) |
mesNombre |
VARCHAR2(20) |
mesNumero |
NUMBER |
anio |
NUMBER |
| Columna | Tipo de datos |
|---|---|
id |
NUMBER |
tienda |
VARCHAR2(30) |
poblacion |
VARCHAR2(30) |
provincia |
VARCHAR2(20) |
comunidadAutonoma |
VARCHAR2(20) |
| Columna | Tipo de datos |
|---|---|
id |
NUMBER |
producto |
VARCHAR2(60) |
familia |
VARCHAR2(30) |
seccion |
VARCHAR2(20) |
| Columna | Tipo de datos |
|---|---|
idCuando |
NUMBER |
idQue |
NUMBER |
idDonde |
NUMBER |
unidades |
NUMBER |
clientes |
NUMBER |
4. Creación de dimensiones
Para la definición de una dimensión en ODI tendremos que especificar:
-
Nombre de la dimensión.
-
Tipo de implementación (estrella o copo de nieve).
-
Datastore. Indica la tabla en el que se va a almacenar la dimensión.
Cada nivel puede tener su propio datastore.
-
Secuencia para la creación de claves generadas.
-
Niveles de la dimensión.
-
Para cada nivel se especifica el datastore que contiene los datos del nivel.
-
En cada nivel se define una clave generada, una clave natural y un atributo que le da nombre al nivel.
-
Cada nivel establece su relación con el nivel superior.
-
-
Jerarquías de la dimensión, estableciendo los niveles que la forman ordenados de nivel superior a nivel inferior.
A continuación crearemos un cubo de Ventas tomando como base los datos de ventas almacenados en el esquema XWEEK. Las tablas de staging están en el esquema BI_SALES.
4.1. Creación de la dimensión Promocion
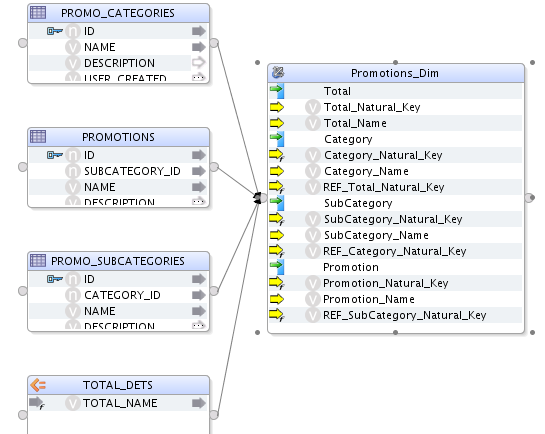
| Nivel | Staging Datastore |
|---|---|
Total |
PROMOTIONS_TOTAL_STG |
Category |
PROMOTIONS_CATEGORY_STG |
Subcategory |
PROMOTIONS_SUBCATEGORY_STG |
Promotion |
PROMOTIONS_PROMOTION_STG |
A continuación, definiremos los atributos de cada nivel:
| Nivel | Nombre | Surrogate Key | Tipo de datos | Atributo |
|---|---|---|---|---|
Total |
Surrogate_Key |
X |
NUMERIC |
TOTAL_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
TOTAL_NATURAL_KEY |
|
Name |
- |
VARCHAR(60) |
TOTAL_NAME |
|
Category |
Surrogate_Key |
X |
NUMERIC |
CATEGORY_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
CATEGORY_NATURAL_KEY |
|
Name |
- |
VARCHAR(60) |
CATEGORY_NAME |
|
Subcategory |
Surrogate_Key |
X |
NUMERIC |
SUBCATEGORY_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
SUBCATEGORY_NATURAL_KEY |
|
Name |
- |
VARCHAR(60) |
SUBCATEGORY_NAME |
|
Promotion |
Surrogate_Key |
X |
NUMERIC |
PROMOTION_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
PROMOTION_NATURAL_KEY |
|
Name |
- |
VARCHAR(60) |
PROMOTION_NAME |
| Nivel | Natural Key Members | Parent References - Name | Parent References - Parent Level |
|---|---|---|---|
Total |
Natural_Key |
- |
- |
Category |
Natural_Key |
Category_of_Total |
Total |
Subcategory |
Natural_Key |
Subcategory_of_category |
Category |
Promotion |
Natural_Key |
Promotion_od_subcategory |
Subcategory |
4.2. Dimensión Canal
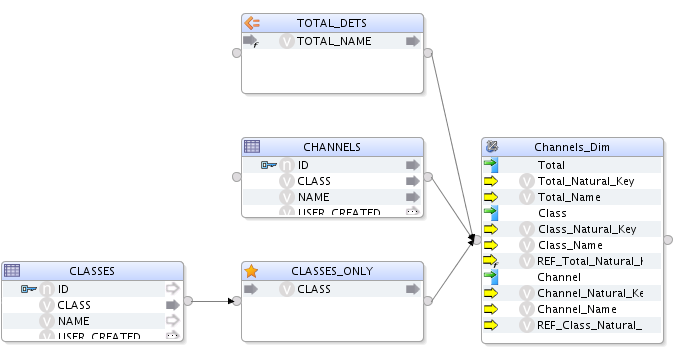
|
|
| Nivel | Staging Datastore |
|---|---|
Total |
CHANNELS_TOTAL_STG |
Class |
CHANNELS_CLASS_STG |
Channel |
CHANNELS_CHANNEL_STG |
A continuación, definiremos los atributos de cada nivel:
| Nivel | Nombre | Surrogate Key | Tipo de datos | Atributo |
|---|---|---|---|---|
Total |
Surrogate_Key |
X |
NUMERIC |
TOTAL_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
TOTAL_NATURAL_KEY |
|
Name |
- |
VARCHAR(60) |
TOTAL_NAME |
|
Class |
Surrogate_Key |
X |
NUMERIC |
CLASS_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
Class_NATURAL_KEY |
|
Name |
- |
VARCHAR(60) |
Class_NAME |
|
Channel |
Surrogate_Key |
X |
NUMERIC |
CHANNEL_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
CHANNEL_NATURAL_KEY |
|
Name |
- |
VARCHAR(60) |
CHANNEL_NAME |
| Nivel | Natural Key Members | Parent References - Name | Parent References - Parent Level |
|---|---|---|---|
Total |
Natural_Key |
- |
- |
Class |
Natural_Key |
Class_of_Total |
Total |
Channel |
Natural_Key |
Channel_of_Class |
Class |
4.3. Dimensión Producto
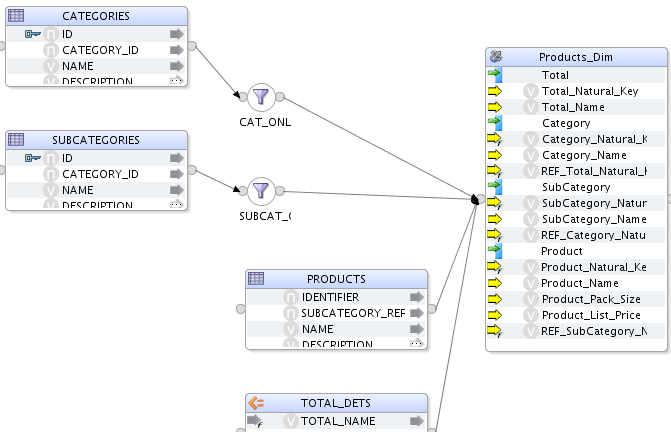
|
|
| Nivel | Staging Datastore |
|---|---|
Total |
PRODUCTS_TOTAL_STG |
Category |
PRODUCTS_CATEGORY_STG |
Subcategory |
PRODUCTS_SUBCATEGORY_STG |
Product |
PRODUCTS_PRODUCT_STG |
A continuación, definiremos los atributos de cada nivel:
| Nivel | Nombre | Surrogate Key | Tipo de datos | Atributo |
|---|---|---|---|---|
Total |
Surrogate_Key |
X |
NUMERIC |
TOTAL_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
TOTAL_NATURAL_KEY |
|
Category |
- |
VARCHAR(60) |
TOTAL_NAME |
|
Category |
Surrogate_Key |
X |
NUMERIC |
CATEGORY_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
CATEGORY_NATURAL_KEY |
|
Name |
- |
VARCHAR(60) |
CATEGORY_NAME |
|
Subcategory |
Surrogate_Key |
X |
NUMERIC |
SUBCATEGORY_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
SUBCATEGORY_NATURAL_KEY |
|
Name |
- |
VARCHAR(60) |
SUBCATEGORY_NAME |
|
Product |
Surrogate_Key |
X |
NUMERIC |
PRODUCT_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
PRODUCT_NATURAL_KEY |
|
Name |
- |
VARCHAR(60) |
PRODUCT_NAME |
|
Pack_Size |
- |
VARCHAR(30) |
SUBCATEGORY_NAME |
|
List_Price |
- |
VARCHAR(30) |
SUBCATEGORY_NAME |
| Nivel | Natural Key Members | Parent References - Name | Parent References - Parent Level |
|---|---|---|---|
Total |
Natural_Key |
- |
- |
Category |
Natural_Key |
Category_of_Total |
Total |
Subcategory |
Natural_Key |
Subcategory_of_Category |
Category |
Product |
Natural_Key |
Product_of_Subcategory |
Subcategory |
4.4. Creación de la dimensión Customer
Vamos a crear la dimensión Customer a partir de la tabla CUSTOMERS_TAB del esquema BI_SALES.
En primer lugar, cerraremos las conexiones existentes en ODI y estableceremos una nueva conexión al repositorio con Login Name Cubes and Dimensions. Se trata de un ejemplo preconfigurado en la máquina virtual de ODI.
En la ficha Designer abrir el bloque Dimensions and Cubes.
4.5. Definición del datastore y la secuencia para las claves generadas
Especificar los valores siguientes en la ficha Definition
| Name | Datastore | Surrogate Key Sequence |
|---|---|---|
Customer |
BI_SALES - CUSTOMERS_TAB |
CUSTOMERS_SEQ |
4.6. Definición de los niveles de las jerarquías
Seleccionar la ficha Levels.
En primer lugar definiremos los niveles de la dimensión:
-
Total
-
Region
-
Subregion
-
Country
-
Province
-
City
-
Customer
| Nivel | Staging Datastore |
|---|---|
Total |
CUSTOMERS_TOTAL_STG |
Region |
CUSTOMERS_REGION_STG |
Subregion |
CUSTOMERS_SUBREGION_STG |
Country |
CUSTOMERS_COUNTRY_STG |
Province |
CUSTOMERS_PROVINCE_STG |
City |
CUSTOMERS_CITY_STG |
Customer |
CUSTOMERS_CUSTOMER_STG |
A continuación, definiremos los atributos de cada nivel:
| Nivel | Nombre | Surrogate Key | Tipo de datos | Atributo |
|---|---|---|---|---|
Total |
Surrogate_Key |
X |
NUMERIC |
TOTAL_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
TOTAL_NATURAL_KEY |
|
Name |
- |
VARCHAR(65) |
TOTAL_NAME |
|
Region |
Surrogate_Key |
X |
NUMERIC |
REGION_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
REGION_NATURAL_KEY |
|
Name |
- |
VARCHAR(65) |
REGION_NAME |
|
Subregion |
Surrogate_Key |
X |
NUMERIC |
SUBREGION_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
SUBREGION_NATURAL_KEY |
|
Name |
- |
VARCHAR(65) |
SUBREGION_NAME |
|
Country |
Surrogate_Key |
X |
NUMERIC |
COUNTRY_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
COUNTRY_NATURAL_KEY |
|
Name |
- |
VARCHAR(65) |
COUNTRY_NAME |
|
ISO |
- |
VARCHAR(2) |
COUNTRY_ISO |
|
Province |
Surrogate_Key |
X |
NUMERIC |
PROVINCE_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
PROVINCE_NATURAL_KEY |
|
Name |
- |
VARCHAR(65) |
PROVINCE_NAME |
|
City |
Surrogate_Key |
X |
NUMERIC |
CITY_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
CITY_NATURAL_KEY |
|
Name |
- |
VARCHAR(65) |
CITY_NAME |
|
Customer |
Surrogate_Key |
X |
NUMERIC |
CUSTOMER_SURROGATE_KEY |
Natural Key |
- |
VARCHAR(40) |
CUSTOMER_NATURAL_KEY |
|
Name |
- |
VARCHAR(65) |
CUSTOMER_NAME |
|
Gender |
- |
VARCHAR(10) |
CUSTOMER_GENDER |
|
Street_Address |
- |
VARCHAR(40) |
CUSTOMER_STREET_ADDRESS |
|
Postal_Code |
- |
VARCHAR(10) |
CUSTOMER_POSTAL_CODE |
|
Phone_Number |
- |
VARCHAR(25) |
CUSTOMER_PHONE_NUMBER |
|
- |
VARCHAR(30) |
CUSTOMER_EMAIL |
| Nivel | Natural Key Members | Parent References - Name | Parent References - Parent Level |
|---|---|---|---|
Total |
Natural_Key |
- |
- |
Region |
Natural_Key |
Region_of_Total |
Total |
Subregion |
Natural_Key |
Subregion_of_Region |
Region |
Country |
Natural_Key |
Country_of_Subregion |
Subregion |
Province |
Natural_Key |
Province_of_Country |
Country |
City |
Natural_Key |
City_of_Province |
Province |
Customer |
Natural_Key |
Customer_of_City |
City |
5. Creación de un cubo
Crearemos un cubo denominado Sales basado en el datastore SALES_TAB.
En la ficha Details definiremos las dimensiones indicando el nivel con el que se relacionan con el cubo de acuerdo con la tabla siguiente:
| Nivel de dimensión | Key Binding Attribute |
|---|---|
Times.Day |
TIMES |
Channels.Channel |
CHANNELS |
Customers.Customer |
CUSTOMERS |
Products.Product |
PRODUCTS |
Promotions.Promotion |
PROMOTIONS |
Las medidas del cubon son:
| Nombre | Tipo de datos | Atributo | Atributo de error |
|---|---|---|---|
Amount |
NUMERIC(10,2) |
AMOUNT |
AMOUNT |
Cost |
NUMERIC(10,2) |
COST |
COST |
Quantity |
NUMERIC |
QUANTITY |
QUANTITY |
6. Creación de mappings
6.1. Mapping de Promotion
Crear un componente EXPRESSION en la zona de mappings añadiéndole un atributo TOTAL_NAME con estas propiedades:
-
Tipo de datos:
VARCHAR(20) -
Expresión:
'Promotions_Total'
| Origen | Destino en dimensión Promotion |
|---|---|
|
|
|
|
|
|
|
|
- |
Cambiar la expresión de |
|
|
|
|
|
|
|
|
|
|
|
|
6.2. Mapping de Canal
Crear un componente EXPRESSION en la zona de mappings añadiéndole un atributo TOTAL_NAME con estas propiedades:
-
Tipo de datos:
VARCHAR(20) -
Expresión:
'Channels_Total'
| Origen | Destino en dimensión Canal |
|---|---|
|
|
|
|
|
|
- |
Cambiar la expresión de |
|
|
|
|
|
|
6.3. Mapping de Producto
Crear un componente EXPRESSION en la zona de mappings añadiéndole un atributo TOTAL_NAME con estas propiedades:
-
Tipo de datos:
VARCHAR(20) -
Expresión:
'Products_Total'
| Origen | Destino en dimensión Promotion |
|---|---|
|
|
|
|
|
|
|
|
- |
Cambiar la expresión de |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
En la ficha Projects, expandir el proyecto OBE, Cubes and Dimensions y hacer clic con el botón derecho en Mappings para seleccionar New Mapping. Introducir Load Customers Dimension.
La dimensión Customer la vamos a cargar con los datos de las tablas siguientes del esquema BI_WEEK.
-
ADDRESSES
-
CITIES
-
COUNTRIES
-
CUSTOMERS
-
REGIONS
6.4. Mapping de Customer
6.4.1. Obtener sólo las provincias
A partir de la tabla CITIES podemos obtener las provincias con sus países con
SELECT DISTINCT STATE_PROVINCE, COUNTRY_ISO_CODE
FROM CITIES;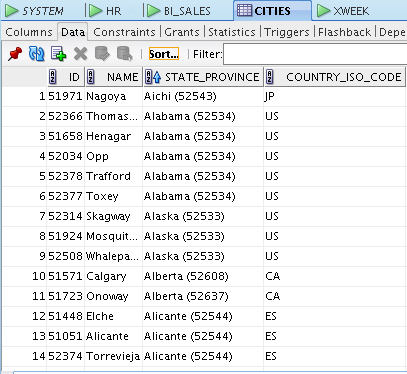
Crear un componente DISTINCT en la zona de mappings incluyendo sólo las columnas STATE_PROVINCE, COUNTRY_ISO_CODE. Renombrar el componente como PROVS_ONLY.
Crear el siguiente mapping:
| Origen | Destino |
|---|---|
CITIES.STATE_PROVINCE |
PROVS_ONLY.STATE_PROVINCE |
CITIES.COUNTRY_ISO_CODE |
PROVS_ONLY.COUNTRY_ISO_CODE |
6.4.2. Creación de joins
Crearemos los siguientes joins mediante componentes JOIN en la zona de mappings:
-
COUNTRIES.ISO_CODE = PROVS_ONLY.COUNTRY_ISO_CODE -
CUSTOMERS.ID = ADDRESSES.CUSTOMER_ID
6.4.3. Obtener las regiones y las subregiones
Si analizamos el contenido de la tabla REGIONS, observamos que las regiones son las que REGION_ID IS NULL, mientras que las subregiones son las que REGION_ID IS NOT NULL.
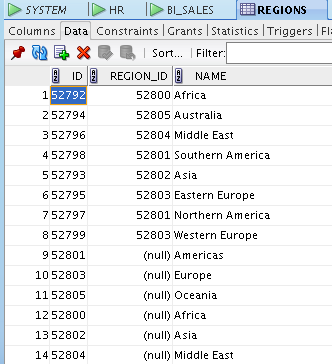
Crearemos dos componentes FILTER en la zona de mappings para obtener sólo las regiones y las subregiones, respectivamente.
| Filtro | Condición de filtrado | Origen |
|---|---|---|
|
|
|
|
|
|
6.4.4. Crear los mappings entre atributos
Crear un componente EXPRESSION en la zona de mappings añadiéndole un atributo TOTAL_NAME con estas propiedades:
-
Tipo de datos:
VARCHAR(20) -
Expresión:
'Customers Total'
A continuación, establecer estos mappings:
| Origen | Destino en dimensión Customers |
|---|---|
|
|
|
|
|
|
|
|
- |
Cambiar la expresión de |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
7. Creación de paquetes
Con los paquetes podemos encadenar la ejecución de mappings. Además, permiten ejecutarlos de forma condicional en función de su ejecución satisfactoria o fallida.
En nuestro caso el paquete ejecutará de forma secuencial los paquetes:
-
Mapping de la dimensión Promocion
-
Mappinc de la dimensión Canal
-
Mapping de la dimensión Producto
-
Mapping de la dimensión Cliente
-
Mapping de la dimensión Fecha
-
Mapping del cubo de ventas
Anexo 1. Scripts para crear las tablas del ejemplo Venta
CREATE TABLE granadam.Cuando (
idCuando NUMBER(12),
diaMes NUMBER(12),
diaSemana VARCHAR2(20),
mesNombre VARCHAR2(20),
mesNumero NUMBER(12),
anio NUMBER(12),
PRIMARY KEY(idCuando)
);
DESCRIBE granadam.Cuando;
SELECT * FROM granadam.Cuando;
CREATE TABLE granadam.Donde (
idDonde NUMBER(12),
tienda VARCHAR2(30),
poblacion VARCHAR2(30),
provincia VARCHAR2(20),
comunidadAutonoma VARCHAR2 (20),
PRIMARY KEY(idDonde)
);
SELECT * FROM granadam.Donde;
describe granadam.Donde;
CREATE TABLE granadam.Que (
idQue NUMBER(12),
producto VARCHAR2(60),
familia VARCHAR2(30),
seccion VARCHAR2(20),
PRIMARY KEY(idQue)
);
SELECT * FROM granadam.Que;
describe granadam.Que;
CREATE TABLE granadam.Venta (
idCuando NUMERIC(12),
idQue NUMERIC(12),
idDonde NUMERIC(12),
unidades NUMERIC(12),
clientes NUMERIC(12),
PRIMARY KEY(idCuando, idQue, idDonde)
);
SELECT * FROM granadam.Venta;
describe granadam.Venta;Anexo 2. Consultas ROLLUP Y CUBE
SELECT diaSemana, familia, SUM(unidades)
FROM Venta, Cuando, Que
WHERE Venta.idCuando = Cuando.idCuando AND
Venta.idQue = Que.idQue
GROUP BY ROLLUP(diaSemana, familia);
SELECT diaSemana, familia, SUM(unidades)
FROM Venta, Cuando, Que
WHERE Venta.idCuando = Cuando.idCuando AND
Venta.idQue = Que.idQue
GROUP BY CUBE(diaSemana, familia);
SELECT diaSemana, familia, SUM(unidades),
GROUPING(diaSemana) as d, GROUPING(familia) as f
FROM Venta, Cuando, Que
WHERE Venta.idCuando = Cuando.idCuando AND
Venta.idQue = Que.idQue
GROUP BY ROLLUP(diaSemana, familia);
SELECT
DECODE(GROUPING(diaSemana), 1, 'Todos los dias', diaSemana) AS diaSemana,
DECODE(GROUPING(familia), 1, 'Todas las familias', familia) AS familia,
SUM(unidades)
FROM Venta, Cuando, Que
WHERE Venta.idCuando = Cuando.idCuando AND
Venta.idQue = Que.idQue
GROUP BY CUBE(diaSemana, familia);Referencias
-
Oracle Data Integrator 12.2.1.2.0. https://docs.oracle.com/middleware/12212/odi/index.html
-
ODI11g: Creating and Connecting to ODI Master and Work Repositories. http://www.oracle.com/webfolder/technetwork/tutorials/obe/fmw/odi/odi_11g/odi_master_work_repos/odi_master_work_repos.htm?print=preview&imgs=visible.
-
ODI 12c - File to Table. http://www.oracle.com/webfolder/technetwork/tutorials/obe/fmw/odi/odi_12c/odi12c_exp_flat_2_tbl/odi12c_exp_flat_2_tbl.html
-
Oracle Data Integrator 12.2.1: Creating Cubes and Dimensions. http://www.oracle.com/webfolder/technetwork/tutorials/obe/fmw/odi/odi_12c/odi_12.2.1.1/Cube_Dimensions/cube_dimensions.html#overview
-
Oracle Database SQL Reference. https://docs.oracle.com/en/database/oracle/oracle-database/12.2/sqlrf/index.html